Ray's Ecosystem and Beyond¶
You can run this notebook directly in
Colab.
![]()
For this chapter you will also need to install the following dependencies:
In [ ]:
Copied!
! pip install "ray[air, serve]==2.2.0" "gradio==3.5.0" "requests==2.28.1"
! pip install "mlflow==1.30.0" "torch==1.12.1" "torchvision==0.13.1"
! pip install "ray[air, serve]==2.2.0" "gradio==3.5.0" "requests==2.28.1"
! pip install "mlflow==1.30.0" "torch==1.12.1" "torchvision==0.13.1"
To import utility files for this chapter, on Colab you will also have to clone the repo and copy the code files to the base path of the runtime:
In [ ]:
Copied!
!git clone https://github.com/maxpumperla/learning_ray
%cp -r learning_ray/notebooks/* .
!git clone https://github.com/maxpumperla/learning_ray
%cp -r learning_ray/notebooks/* .
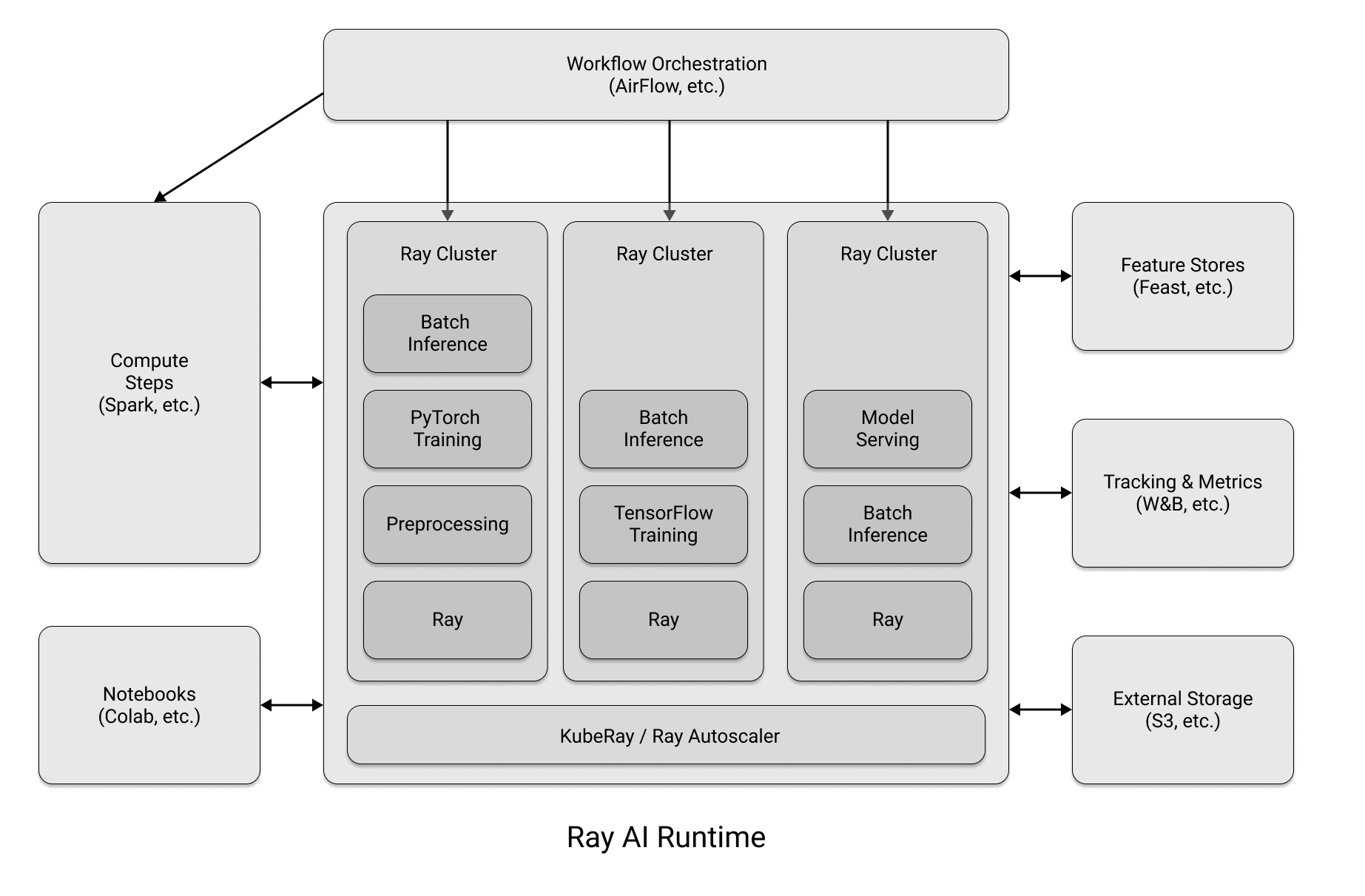
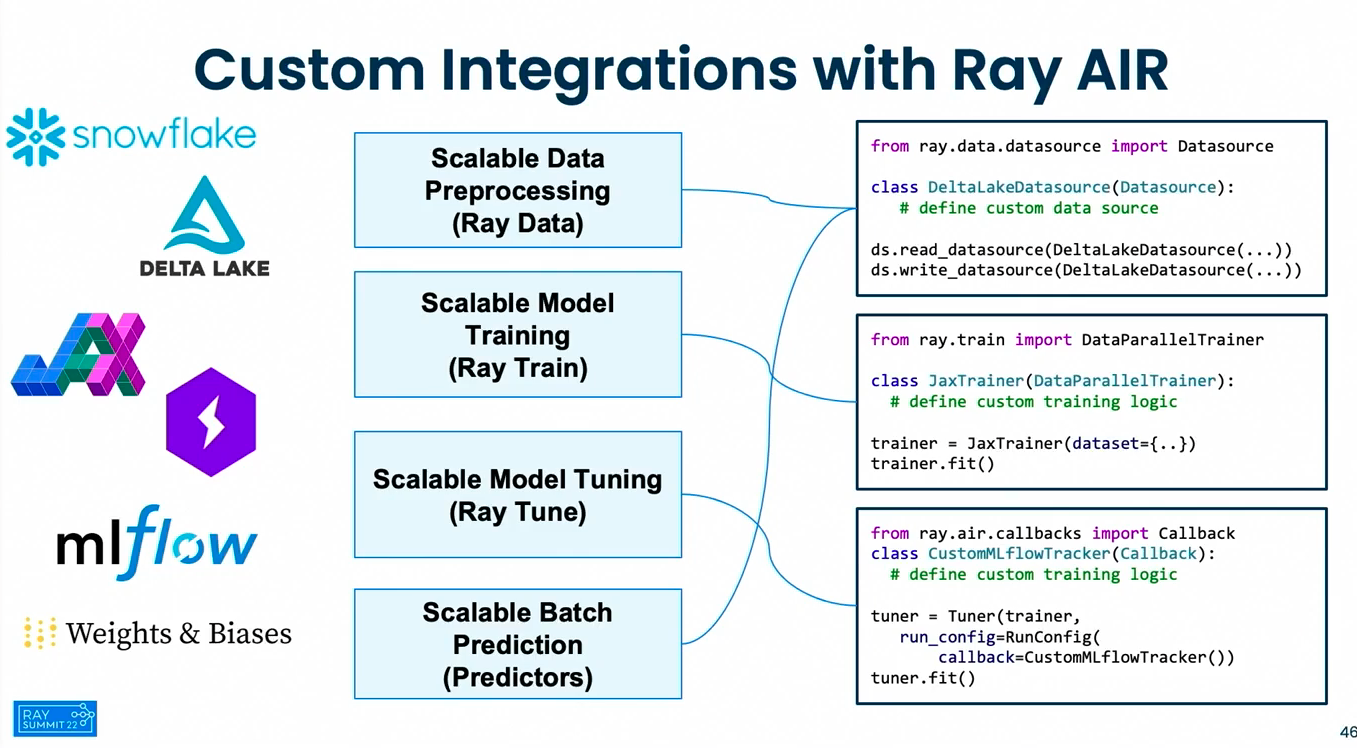
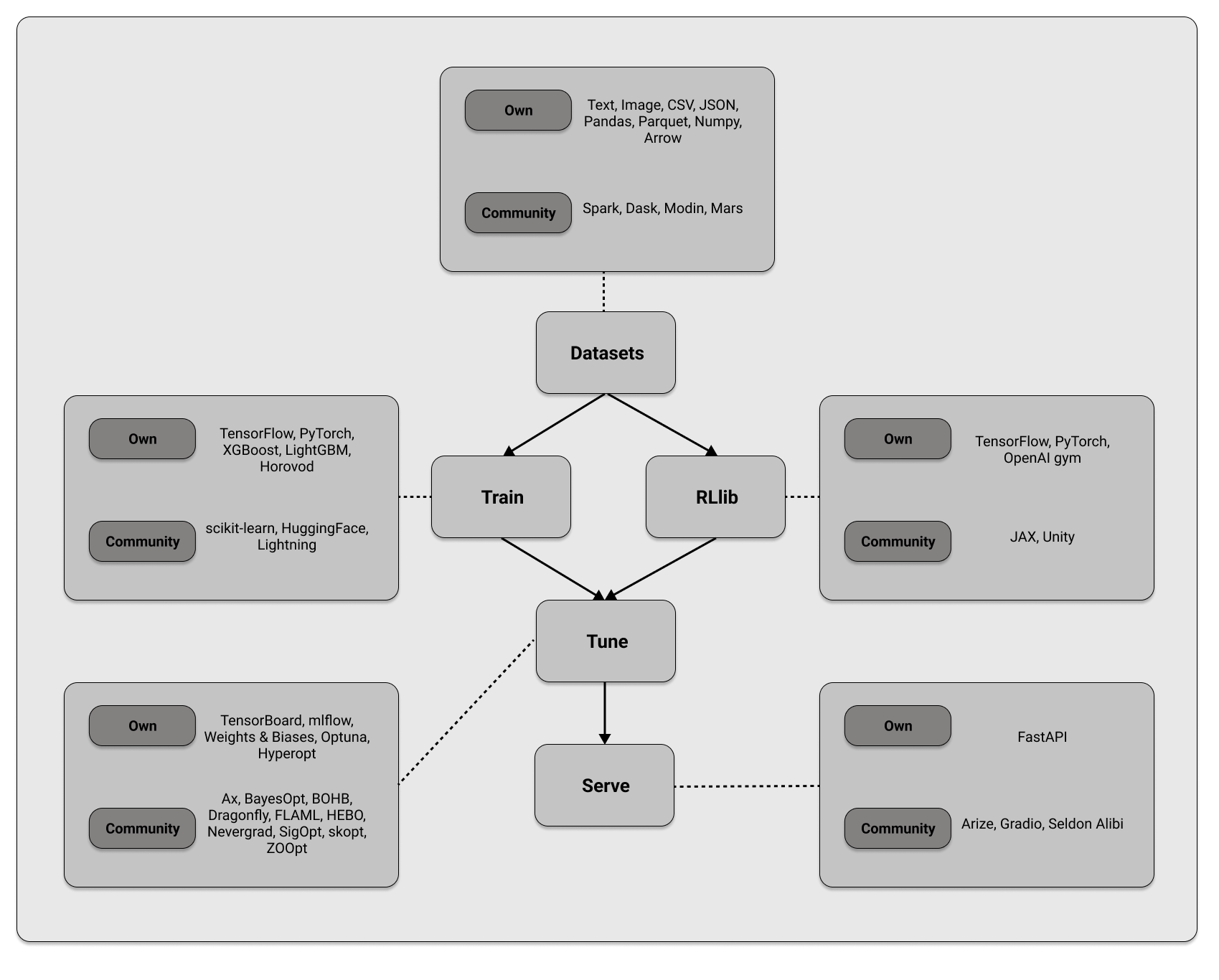
In [ ]:
Copied!
from torchvision import transforms, datasets
def load_cifar(train: bool):
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
return datasets.CIFAR10(
root="./data",
download=True,
train=train,
transform=transform
)
from torchvision import transforms, datasets
def load_cifar(train: bool):
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
return datasets.CIFAR10(
root="./data",
download=True,
train=train,
transform=transform
)
In [ ]:
Copied!
from ray.data import from_torch
train_dataset = from_torch(load_cifar(train=True))
test_dataset = from_torch(load_cifar(train=False))
from ray.data import from_torch
train_dataset = from_torch(load_cifar(train=True))
test_dataset = from_torch(load_cifar(train=False))
In [ ]:
Copied!
import numpy as np
def to_labeled_image(batch):
return {
"image": np.array([image.numpy() for image, _ in batch]),
"label": np.array([label for _, label in batch]),
}
train_dataset = train_dataset.map_batches(to_labeled_image)
test_dataset = test_dataset.map_batches(to_labeled_image)
import numpy as np
def to_labeled_image(batch):
return {
"image": np.array([image.numpy() for image, _ in batch]),
"label": np.array([label for _, label in batch]),
}
train_dataset = train_dataset.map_batches(to_labeled_image)
test_dataset = test_dataset.map_batches(to_labeled_image)
In [ ]:
Copied!
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
In [ ]:
Copied!
from ray import train
from ray.air import session, Checkpoint
def train_loop(config):
model = train.torch.prepare_model(Net())
loss_fct = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
train_batches = session.get_dataset_shard("train").iter_torch_batches(
batch_size=config["batch_size"],
)
for epoch in range(config["epochs"]):
running_loss = 0.0
for i, data in enumerate(train_batches):
inputs, labels = data["image"], data["label"]
optimizer.zero_grad()
forward_outputs = model(inputs)
loss = loss_fct(forward_outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 1000 == 0:
print(f"[{epoch + 1}, {i + 1:4d}] loss: "
f"{running_loss / 1000:.3f}")
running_loss = 0.0
session.report(
dict(running_loss=running_loss),
checkpoint=Checkpoint.from_dict(
dict(model=model.module.state_dict())
),
)
from ray import train
from ray.air import session, Checkpoint
def train_loop(config):
model = train.torch.prepare_model(Net())
loss_fct = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
train_batches = session.get_dataset_shard("train").iter_torch_batches(
batch_size=config["batch_size"],
)
for epoch in range(config["epochs"]):
running_loss = 0.0
for i, data in enumerate(train_batches):
inputs, labels = data["image"], data["label"]
optimizer.zero_grad()
forward_outputs = model(inputs)
loss = loss_fct(forward_outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 1000 == 0:
print(f"[{epoch + 1}, {i + 1:4d}] loss: "
f"{running_loss / 1000:.3f}")
running_loss = 0.0
session.report(
dict(running_loss=running_loss),
checkpoint=Checkpoint.from_dict(
dict(model=model.module.state_dict())
),
)
In [ ]:
Copied!
from ray.train.torch import TorchTrainer
from ray.air.config import ScalingConfig, RunConfig
from ray.air.callbacks.mlflow import MLflowLoggerCallback
trainer = TorchTrainer(
train_loop_per_worker=train_loop,
train_loop_config={"batch_size": 10, "epochs": 5},
datasets={"train": train_dataset},
scaling_config=ScalingConfig(num_workers=2),
run_config=RunConfig(callbacks=[
MLflowLoggerCallback(experiment_name="torch_trainer")
])
)
result = trainer.fit()
from ray.train.torch import TorchTrainer
from ray.air.config import ScalingConfig, RunConfig
from ray.air.callbacks.mlflow import MLflowLoggerCallback
trainer = TorchTrainer(
train_loop_per_worker=train_loop,
train_loop_config={"batch_size": 10, "epochs": 5},
datasets={"train": train_dataset},
scaling_config=ScalingConfig(num_workers=2),
run_config=RunConfig(callbacks=[
MLflowLoggerCallback(experiment_name="torch_trainer")
])
)
result = trainer.fit()
In [ ]:
Copied!
CHECKPOINT_PATH = "torch_checkpoint"
result.checkpoint.to_directory(CHECKPOINT_PATH)
CHECKPOINT_PATH = "torch_checkpoint"
result.checkpoint.to_directory(CHECKPOINT_PATH)
If you run this notebook in Colab, please make sure the "torch_checkpoint" gets generated properly. The folder needs an ".is_checkpoint" file in it, as well as ".tune_metadata" and a "dict_checkpoint.pkl". The gradio demo will throw an error on faulty checkpoints.
In [ ]:
Copied!
# Note: if the checkpoint didn't get generated properly, you will get a "pickle" error here.
! serve run --non-blocking gradio_demo:app
# Note: if the checkpoint didn't get generated properly, you will get a "pickle" error here.
! serve run --non-blocking gradio_demo:app
In [ ]:
Copied!
from ray.data import read_datasource, datasource
class SnowflakeDatasource(datasource.Datasource):
pass
dataset = read_datasource(SnowflakeDatasource(), ...)
from ray.data import read_datasource, datasource
class SnowflakeDatasource(datasource.Datasource):
pass
dataset = read_datasource(SnowflakeDatasource(), ...)
In [ ]:
Copied!
from ray.train.data_parallel_trainer import DataParallelTrainer
class JaxTrainer(DataParallelTrainer):
pass
trainer = JaxTrainer(
...,
scaling_config=ScalingConfig(...),
datasets=dict(train=dataset),
)
from ray.train.data_parallel_trainer import DataParallelTrainer
class JaxTrainer(DataParallelTrainer):
pass
trainer = JaxTrainer(
...,
scaling_config=ScalingConfig(...),
datasets=dict(train=dataset),
)
In [ ]:
Copied!
from ray.tune import logger, tuner
from ray.air.config import RunConfig
class NeptuneCallback(logger.LoggerCallback):
pass
tuner = tuner.Tuner(
trainer,
run_config=RunConfig(callbacks=[NeptuneCallback()])
)
from ray.tune import logger, tuner
from ray.air.config import RunConfig
class NeptuneCallback(logger.LoggerCallback):
pass
tuner = tuner.Tuner(
trainer,
run_config=RunConfig(callbacks=[NeptuneCallback()])
)