Distributed Training with Ray Train¶
You can run this notebook directly in
Colab.
![]()
For this chapter you will need to install the following dependencies:
In [ ]:
Copied!
! pip install "ray[data,train]==2.2.0" "dask==2022.2.0" "torch==1.12.1"
! pip install "xgboost==1.6.2" "xgboost-ray>=0.1.10"
! pip install "ray[data,train]==2.2.0" "dask==2022.2.0" "torch==1.12.1"
! pip install "xgboost==1.6.2" "xgboost-ray>=0.1.10"
To import utility files for this chapter, on Colab you will also have to clone the repo and copy the code files to the base path of the runtime:
In [ ]:
Copied!
!git clone https://github.com/maxpumperla/learning_ray
%cp -r learning_ray/notebooks/* .
!git clone https://github.com/maxpumperla/learning_ray
%cp -r learning_ray/notebooks/* .
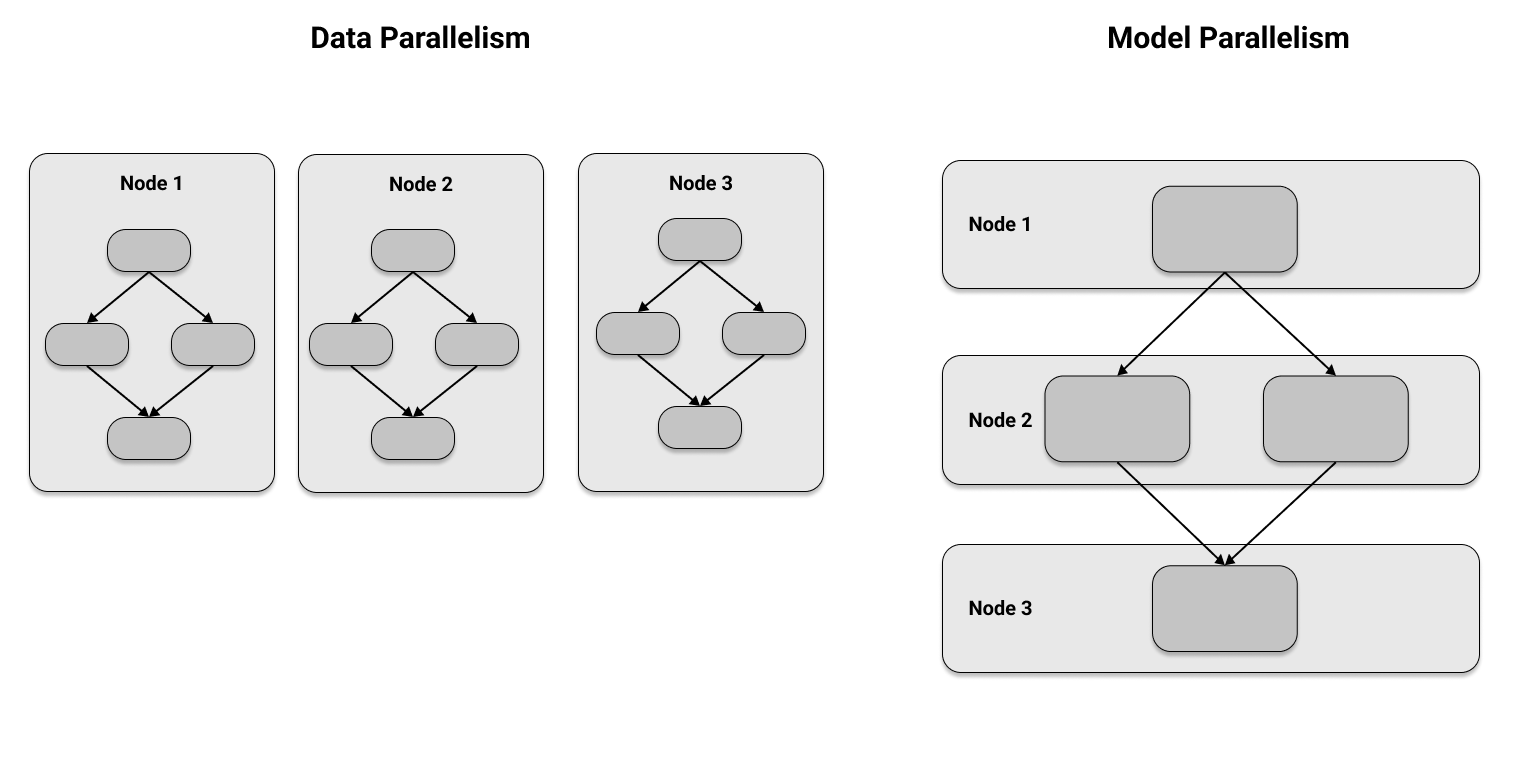
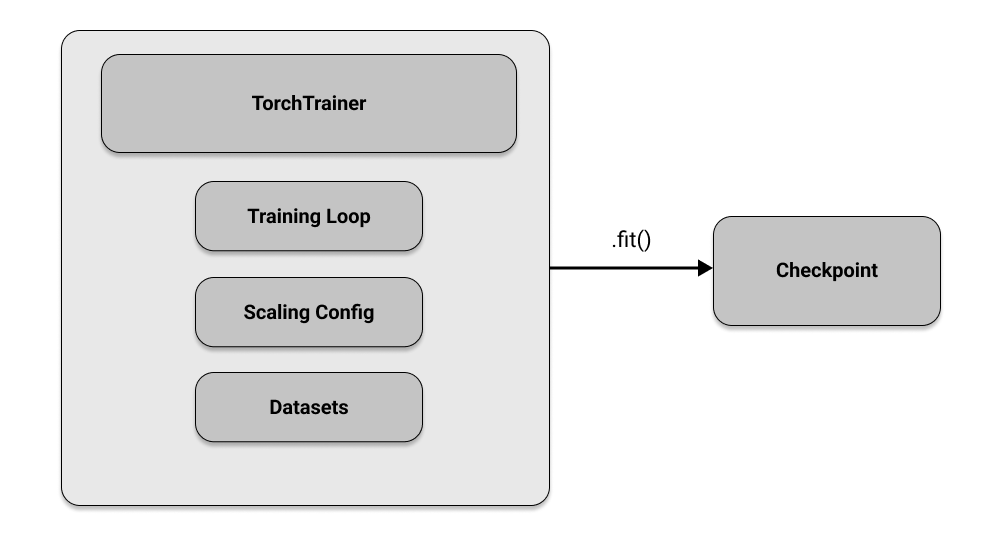
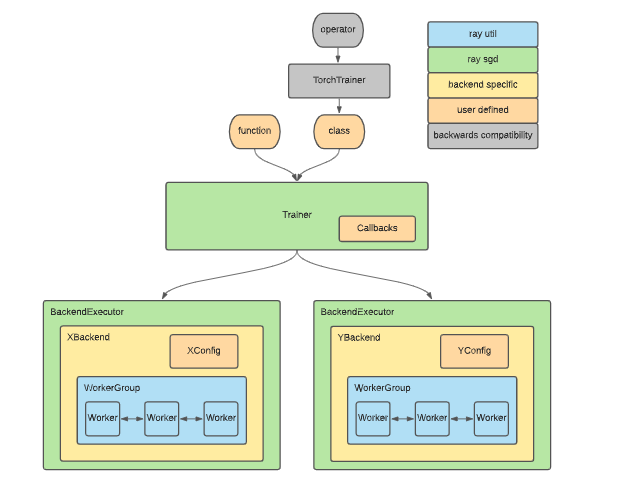
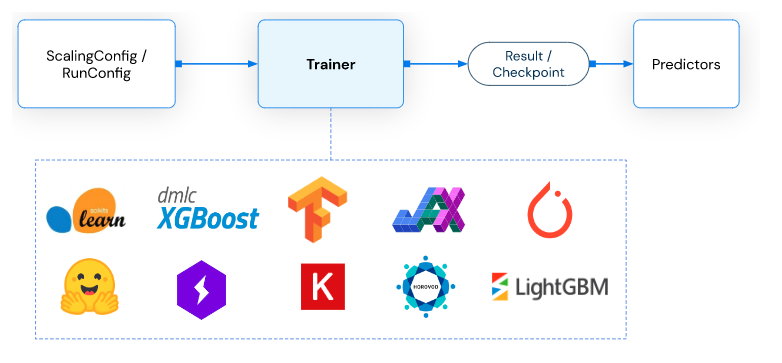
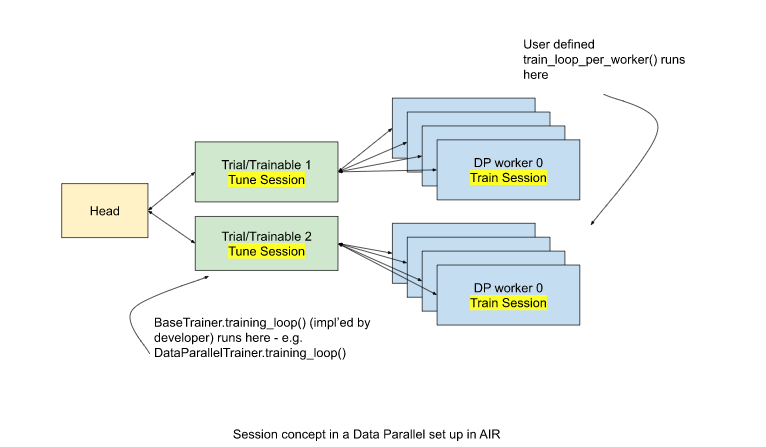
In [ ]:
Copied!
import ray
from ray.util.dask import enable_dask_on_ray
import dask.dataframe as dd
LABEL_COLUMN = "is_big_tip"
FEATURE_COLUMNS = ["passenger_count", "trip_distance", "fare_amount",
"trip_duration", "hour", "day_of_week"]
enable_dask_on_ray()
def load_dataset(path: str, *, include_label=True):
columns = ["tpep_pickup_datetime", "tpep_dropoff_datetime", "tip_amount",
"passenger_count", "trip_distance", "fare_amount"]
df = dd.read_parquet(path, columns=columns)
df = df.dropna()
df = df[(df["passenger_count"] <= 4) &
(df["trip_distance"] < 100) &
(df["fare_amount"] < 1000)]
df["tpep_pickup_datetime"] = dd.to_datetime(df["tpep_pickup_datetime"])
df["tpep_dropoff_datetime"] = dd.to_datetime(df["tpep_dropoff_datetime"])
df["trip_duration"] = (df["tpep_dropoff_datetime"] -
df["tpep_pickup_datetime"]).dt.seconds
df = df[df["trip_duration"] < 4 * 60 * 60] # 4 hours.
df["hour"] = df["tpep_pickup_datetime"].dt.hour
df["day_of_week"] = df["tpep_pickup_datetime"].dt.weekday
if include_label:
df[LABEL_COLUMN] = df["tip_amount"] > 0.2 * df["fare_amount"]
df = df.drop(
columns=["tpep_pickup_datetime", "tpep_dropoff_datetime", "tip_amount"]
)
return ray.data.from_dask(df).repartition(100)
import ray
from ray.util.dask import enable_dask_on_ray
import dask.dataframe as dd
LABEL_COLUMN = "is_big_tip"
FEATURE_COLUMNS = ["passenger_count", "trip_distance", "fare_amount",
"trip_duration", "hour", "day_of_week"]
enable_dask_on_ray()
def load_dataset(path: str, *, include_label=True):
columns = ["tpep_pickup_datetime", "tpep_dropoff_datetime", "tip_amount",
"passenger_count", "trip_distance", "fare_amount"]
df = dd.read_parquet(path, columns=columns)
df = df.dropna()
df = df[(df["passenger_count"] <= 4) &
(df["trip_distance"] < 100) &
(df["fare_amount"] < 1000)]
df["tpep_pickup_datetime"] = dd.to_datetime(df["tpep_pickup_datetime"])
df["tpep_dropoff_datetime"] = dd.to_datetime(df["tpep_dropoff_datetime"])
df["trip_duration"] = (df["tpep_dropoff_datetime"] -
df["tpep_pickup_datetime"]).dt.seconds
df = df[df["trip_duration"] < 4 * 60 * 60] # 4 hours.
df["hour"] = df["tpep_pickup_datetime"].dt.hour
df["day_of_week"] = df["tpep_pickup_datetime"].dt.weekday
if include_label:
df[LABEL_COLUMN] = df["tip_amount"] > 0.2 * df["fare_amount"]
df = df.drop(
columns=["tpep_pickup_datetime", "tpep_dropoff_datetime", "tip_amount"]
)
return ray.data.from_dask(df).repartition(100)
In [ ]:
Copied!
import torch
import torch.nn as nn
import torch.nn.functional as F
class FarePredictor(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(6, 256)
self.fc2 = nn.Linear(256, 16)
self.fc3 = nn.Linear(16, 1)
self.bn1 = nn.BatchNorm1d(256)
self.bn2 = nn.BatchNorm1d(16)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.bn1(x)
x = F.relu(self.fc2(x))
x = self.bn2(x)
x = torch.sigmoid(self.fc3(x))
return x
import torch
import torch.nn as nn
import torch.nn.functional as F
class FarePredictor(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(6, 256)
self.fc2 = nn.Linear(256, 16)
self.fc3 = nn.Linear(16, 1)
self.bn1 = nn.BatchNorm1d(256)
self.bn2 = nn.BatchNorm1d(16)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.bn1(x)
x = F.relu(self.fc2(x))
x = self.bn2(x)
x = torch.sigmoid(self.fc3(x))
return x
In [ ]:
Copied!
from ray.air import session
from ray.air.config import ScalingConfig
import ray.train as train
from ray.train.torch import TorchCheckpoint, TorchTrainer
def train_loop_per_worker(config: dict):
batch_size = config.get("batch_size", 32)
lr = config.get("lr", 1e-2)
num_epochs = config.get("num_epochs", 3)
dataset_shard = session.get_dataset_shard("train")
model = FarePredictor()
dist_model = train.torch.prepare_model(model)
loss_function = nn.SmoothL1Loss()
optimizer = torch.optim.Adam(dist_model.parameters(), lr=lr)
for epoch in range(num_epochs):
loss = 0
num_batches = 0
for batch in dataset_shard.iter_torch_batches(
batch_size=batch_size, dtypes=torch.float
):
labels = torch.unsqueeze(batch[LABEL_COLUMN], dim=1)
inputs = torch.cat(
[torch.unsqueeze(batch[f], dim=1) for f in FEATURE_COLUMNS], dim=1
)
output = dist_model(inputs)
batch_loss = loss_function(output, labels)
optimizer.zero_grad()
batch_loss.backward()
optimizer.step()
num_batches += 1
loss += batch_loss.item()
session.report(
{"epoch": epoch, "loss": loss},
checkpoint=TorchCheckpoint.from_model(dist_model)
)
from ray.air import session
from ray.air.config import ScalingConfig
import ray.train as train
from ray.train.torch import TorchCheckpoint, TorchTrainer
def train_loop_per_worker(config: dict):
batch_size = config.get("batch_size", 32)
lr = config.get("lr", 1e-2)
num_epochs = config.get("num_epochs", 3)
dataset_shard = session.get_dataset_shard("train")
model = FarePredictor()
dist_model = train.torch.prepare_model(model)
loss_function = nn.SmoothL1Loss()
optimizer = torch.optim.Adam(dist_model.parameters(), lr=lr)
for epoch in range(num_epochs):
loss = 0
num_batches = 0
for batch in dataset_shard.iter_torch_batches(
batch_size=batch_size, dtypes=torch.float
):
labels = torch.unsqueeze(batch[LABEL_COLUMN], dim=1)
inputs = torch.cat(
[torch.unsqueeze(batch[f], dim=1) for f in FEATURE_COLUMNS], dim=1
)
output = dist_model(inputs)
batch_loss = loss_function(output, labels)
optimizer.zero_grad()
batch_loss.backward()
optimizer.step()
num_batches += 1
loss += batch_loss.item()
session.report(
{"epoch": epoch, "loss": loss},
checkpoint=TorchCheckpoint.from_model(dist_model)
)
In [ ]:
Copied!
# NOTE: In the book we use num_workers=2, but reduce this here, so that it runs on Colab.
# In any case, this training loop will take considerable time to run.
trainer = TorchTrainer(
train_loop_per_worker=train_loop_per_worker,
train_loop_config={
"lr": 1e-2, "num_epochs": 3, "batch_size": 64
},
scaling_config=ScalingConfig(num_workers=1, resources_per_worker={"CPU": 1, "GPU": 0}),
datasets={
"train": load_dataset("nyc_tlc_data/yellow_tripdata_2020-01.parquet")
},
)
result = trainer.fit()
trained_model = result.checkpoint
# NOTE: In the book we use num_workers=2, but reduce this here, so that it runs on Colab.
# In any case, this training loop will take considerable time to run.
trainer = TorchTrainer(
train_loop_per_worker=train_loop_per_worker,
train_loop_config={
"lr": 1e-2, "num_epochs": 3, "batch_size": 64
},
scaling_config=ScalingConfig(num_workers=1, resources_per_worker={"CPU": 1, "GPU": 0}),
datasets={
"train": load_dataset("nyc_tlc_data/yellow_tripdata_2020-01.parquet")
},
)
result = trainer.fit()
trained_model = result.checkpoint
In [ ]:
Copied!
from ray.train.torch import TorchPredictor
from ray.train.batch_predictor import BatchPredictor
batch_predictor = BatchPredictor(trained_model, TorchPredictor)
ds = load_dataset(
"nyc_tlc_data/yellow_tripdata_2021-01.parquet", include_label=False)
batch_predictor.predict_pipelined(ds, blocks_per_window=10)
from ray.train.torch import TorchPredictor
from ray.train.batch_predictor import BatchPredictor
batch_predictor = BatchPredictor(trained_model, TorchPredictor)
ds = load_dataset(
"nyc_tlc_data/yellow_tripdata_2021-01.parquet", include_label=False)
batch_predictor.predict_pipelined(ds, blocks_per_window=10)
In [ ]:
Copied!
import torch
import torch.nn as nn
import torch.nn.functional as F
from ray.data import from_torch
num_samples = 20
input_size = 10
layer_size = 15
output_size = 5
num_epochs = 3
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(input_size, layer_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(layer_size, output_size)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
def train_data():
return torch.randn(num_samples, input_size)
input_data = train_data()
label_data = torch.randn(num_samples, output_size)
train_dataset = from_torch(input_data)
def train_one_epoch(model, loss_fn, optimizer):
output = model(input_data)
loss = loss_fn(output, label_data)
optimizer.zero_grad()
loss.backward()
optimizer.step()
def training_loop():
model = NeuralNetwork()
loss_fn = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
for epoch in range(num_epochs):
train_one_epoch(model, loss_fn, optimizer)
import torch
import torch.nn as nn
import torch.nn.functional as F
from ray.data import from_torch
num_samples = 20
input_size = 10
layer_size = 15
output_size = 5
num_epochs = 3
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(input_size, layer_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(layer_size, output_size)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
def train_data():
return torch.randn(num_samples, input_size)
input_data = train_data()
label_data = torch.randn(num_samples, output_size)
train_dataset = from_torch(input_data)
def train_one_epoch(model, loss_fn, optimizer):
output = model(input_data)
loss = loss_fn(output, label_data)
optimizer.zero_grad()
loss.backward()
optimizer.step()
def training_loop():
model = NeuralNetwork()
loss_fn = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
for epoch in range(num_epochs):
train_one_epoch(model, loss_fn, optimizer)
In [ ]:
Copied!
from ray.train.torch import prepare_model
def distributed_training_loop():
model = NeuralNetwork()
model = prepare_model(model)
loss_fn = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
for epoch in range(num_epochs):
train_one_epoch(model, loss_fn, optimizer)
from ray.train.torch import prepare_model
def distributed_training_loop():
model = NeuralNetwork()
model = prepare_model(model)
loss_fn = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
for epoch in range(num_epochs):
train_one_epoch(model, loss_fn, optimizer)
In [ ]:
Copied!
from ray.air.config import ScalingConfig
from ray.train.torch import TorchTrainer
trainer = TorchTrainer(
train_loop_per_worker=distributed_training_loop,
scaling_config=ScalingConfig(
num_workers=2,
use_gpu=False
),
datasets={"train": train_dataset}
)
result = trainer.fit()
from ray.air.config import ScalingConfig
from ray.train.torch import TorchTrainer
trainer = TorchTrainer(
train_loop_per_worker=distributed_training_loop,
scaling_config=ScalingConfig(
num_workers=2,
use_gpu=False
),
datasets={"train": train_dataset}
)
result = trainer.fit()
In [ ]:
Copied!
import ray
from ray.air.config import ScalingConfig
from ray import tune
from ray.data.preprocessors import StandardScaler, MinMaxScaler
dataset = ray.data.from_items(
[{"X": x, "Y": 1} for x in range(0, 100)] +
[{"X": x, "Y": 0} for x in range(100, 200)]
)
prep_v1 = StandardScaler(columns=["X"])
prep_v2 = MinMaxScaler(columns=["X"])
param_space = {
"scaling_config": ScalingConfig(
num_workers=tune.grid_search([2, 4]),
resources_per_worker={
"CPU": 2,
"GPU": 0,
},
),
"preprocessor": tune.grid_search([prep_v1, prep_v2]),
"params": {
"objective": "binary:logistic",
"tree_method": "hist",
"eval_metric": ["logloss", "error"],
"eta": tune.loguniform(1e-4, 1e-1),
"subsample": tune.uniform(0.5, 1.0),
"max_depth": tune.randint(1, 9),
},
}
import ray
from ray.air.config import ScalingConfig
from ray import tune
from ray.data.preprocessors import StandardScaler, MinMaxScaler
dataset = ray.data.from_items(
[{"X": x, "Y": 1} for x in range(0, 100)] +
[{"X": x, "Y": 0} for x in range(100, 200)]
)
prep_v1 = StandardScaler(columns=["X"])
prep_v2 = MinMaxScaler(columns=["X"])
param_space = {
"scaling_config": ScalingConfig(
num_workers=tune.grid_search([2, 4]),
resources_per_worker={
"CPU": 2,
"GPU": 0,
},
),
"preprocessor": tune.grid_search([prep_v1, prep_v2]),
"params": {
"objective": "binary:logistic",
"tree_method": "hist",
"eval_metric": ["logloss", "error"],
"eta": tune.loguniform(1e-4, 1e-1),
"subsample": tune.uniform(0.5, 1.0),
"max_depth": tune.randint(1, 9),
},
}
In [ ]:
Copied!
from ray.train.xgboost import XGBoostTrainer
from ray.air.config import RunConfig
from ray.tune import Tuner
trainer = XGBoostTrainer(
params={},
run_config=RunConfig(verbose=2),
preprocessor=None,
scaling_config=None,
label_column="Y",
datasets={"train": dataset}
)
tuner = Tuner(
trainer,
param_space=param_space,
)
results = tuner.fit()
from ray.train.xgboost import XGBoostTrainer
from ray.air.config import RunConfig
from ray.tune import Tuner
trainer = XGBoostTrainer(
params={},
run_config=RunConfig(verbose=2),
preprocessor=None,
scaling_config=None,
label_column="Y",
datasets={"train": dataset}
)
tuner = Tuner(
trainer,
param_space=param_space,
)
results = tuner.fit()