Data Processing with Ray¶
You can run this notebook directly in
Colab.
![]()
For this chapter you need to install the following dependencies:
In [ ]:
Copied!
! pip install "ray[data]==2.2.0"
! pip install "scikit-learn==1.0.2"
! pip install "dask==2022.2.0"
! pip install "ray[data]==2.2.0"
! pip install "scikit-learn==1.0.2"
! pip install "dask==2022.2.0"
To import utility files for this chapter, on Colab you will also have to clone the repo and copy the code files to the base path of the runtime:
In [ ]:
Copied!
!git clone https://github.com/maxpumperla/learning_ray
%cp -r learning_ray/notebooks/* .
!git clone https://github.com/maxpumperla/learning_ray
%cp -r learning_ray/notebooks/* .

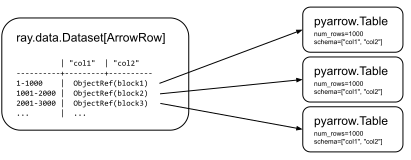
In [ ]:
Copied!
import ray
# Create a dataset containing integers in the range [0, 10000).
ds = ray.data.range(10000)
# Basic operations: show the size of the dataset, get a few samples, print the schema.
print(ds.count()) # -> 10000
print(ds.take(5)) # -> [0, 1, 2, 3, 4]
print(ds.schema()) # -> <class 'int'>
import ray
# Create a dataset containing integers in the range [0, 10000).
ds = ray.data.range(10000)
# Basic operations: show the size of the dataset, get a few samples, print the schema.
print(ds.count()) # -> 10000
print(ds.take(5)) # -> [0, 1, 2, 3, 4]
print(ds.schema()) # ->
In [ ]:
Copied!
# Save the dataset to a local file and load it back.
ray.data.range(10000).write_csv("local_dir")
ds = ray.data.read_csv("local_dir")
print(ds.count())
# Save the dataset to a local file and load it back.
ray.data.range(10000).write_csv("local_dir")
ds = ray.data.read_csv("local_dir")
print(ds.count())
In [ ]:
Copied!
ds1 = ray.data.range(10000)
ds2 = ray.data.range(10000)
ds3 = ds1.union(ds2)
print(ds3.count()) # -> 20000
# Filter the combined dataset to only the even elements.
ds3 = ds3.filter(lambda x: x % 2 == 0)
print(ds3.count()) # -> 10000
print(ds3.take(5)) # -> [0, 2, 4, 6, 8]
# Sort the filtered dataset.
ds3 = ds3.sort() # <3>
print(ds3.take(5)) # -> [0, 0, 2, 2, 4]
ds1 = ray.data.range(10000)
ds2 = ray.data.range(10000)
ds3 = ds1.union(ds2)
print(ds3.count()) # -> 20000
# Filter the combined dataset to only the even elements.
ds3 = ds3.filter(lambda x: x % 2 == 0)
print(ds3.count()) # -> 10000
print(ds3.take(5)) # -> [0, 2, 4, 6, 8]
# Sort the filtered dataset.
ds3 = ds3.sort() # <3>
print(ds3.take(5)) # -> [0, 0, 2, 2, 4]
In [ ]:
Copied!
ds1 = ray.data.range(10000)
print(ds1.num_blocks()) # -> 200
ds2 = ray.data.range(10000)
print(ds2.num_blocks()) # -> 200
ds3 = ds1.union(ds2)
print(ds3.num_blocks()) # -> 400
print(ds3.repartition(200).num_blocks()) # -> 200
ds1 = ray.data.range(10000)
print(ds1.num_blocks()) # -> 200
ds2 = ray.data.range(10000)
print(ds2.num_blocks()) # -> 200
ds3 = ds1.union(ds2)
print(ds3.num_blocks()) # -> 400
print(ds3.repartition(200).num_blocks()) # -> 200
In [ ]:
Copied!
ds = ray.data.from_items([{"id": "abc", "value": 1}, {"id": "def", "value": 2}])
print(ds.schema()) # -> id: string, value: int64
ds = ray.data.from_items([{"id": "abc", "value": 1}, {"id": "def", "value": 2}])
print(ds.schema()) # -> id: string, value: int64
In [ ]:
Copied!
pandas_df = ds.to_pandas() # pandas_df will inherit the schema from our Dataset.
pandas_df = ds.to_pandas() # pandas_df will inherit the schema from our Dataset.
In [ ]:
Copied!
ds = ray.data.range(10000).map(lambda x: x ** 2)
ds.take(5) # -> [0, 1, 4, 9, 16]
ds = ray.data.range(10000).map(lambda x: x ** 2)
ds.take(5) # -> [0, 1, 4, 9, 16]
In [ ]:
Copied!
import numpy as np
ds = ray.data.range(10000).map_batches(lambda batch: np.square(batch).tolist())
ds.take(5) # -> [0, 1, 4, 9, 16]
import numpy as np
ds = ray.data.range(10000).map_batches(lambda batch: np.square(batch).tolist())
ds.take(5) # -> [0, 1, 4, 9, 16]
In [ ]:
Copied!
def load_model():
# Returns a dummy model for this example.
# In reality, this would likely load some model weights onto a GPU.
class DummyModel:
def __call__(self, batch):
return batch
return DummyModel()
class MLModel:
def __init__(self):
# load_model() will only run once per actor that's started.
self._model = load_model()
def __call__(self, batch):
return self._model(batch)
ds.map_batches(MLModel, compute="actors")
cpu_intensive_preprocessing = lambda batch: batch
gpu_intensive_inference = lambda batch: batch
def load_model():
# Returns a dummy model for this example.
# In reality, this would likely load some model weights onto a GPU.
class DummyModel:
def __call__(self, batch):
return batch
return DummyModel()
class MLModel:
def __init__(self):
# load_model() will only run once per actor that's started.
self._model = load_model()
def __call__(self, batch):
return self._model(batch)
ds.map_batches(MLModel, compute="actors")
cpu_intensive_preprocessing = lambda batch: batch
gpu_intensive_inference = lambda batch: batch
In [ ]:
Copied!
# NOTE: this only works if you create an S3 bucket and upload the data there.
ds = (ray.data.read_parquet("s3://my_bucket/input_data")
.map(cpu_intensive_preprocessing)
.map_batches(gpu_intensive_inference, compute="actors", num_gpus=1)
.repartition(10))
ds.write_parquet("s3://my_bucket/output_predictions")
# NOTE: this only works if you create an S3 bucket and upload the data there.
ds = (ray.data.read_parquet("s3://my_bucket/input_data")
.map(cpu_intensive_preprocessing)
.map_batches(gpu_intensive_inference, compute="actors", num_gpus=1)
.repartition(10))
ds.write_parquet("s3://my_bucket/output_predictions")
In [ ]:
Copied!
# NOTE: this only works if you create an S3 bucket and upload the data there.
ds = (ray.data.read_parquet("s3://my_bucket/input_data")
.window(blocks_per_window=5)
.map(cpu_intensive_preprocessing)
.map_batches(gpu_intensive_inference, compute="actors", num_gpus=1)
.repartition(10))
ds.write_parquet("s3://my_bucket/output_predictions")
# NOTE: this only works if you create an S3 bucket and upload the data there.
ds = (ray.data.read_parquet("s3://my_bucket/input_data")
.window(blocks_per_window=5)
.map(cpu_intensive_preprocessing)
.map_batches(gpu_intensive_inference, compute="actors", num_gpus=1)
.repartition(10))
ds.write_parquet("s3://my_bucket/output_predictions")
In [ ]:
Copied!
from sklearn import datasets
from sklearn.linear_model import SGDClassifier
from sklearn.model_selection import train_test_split
@ray.remote
class TrainingWorker:
def __init__(self, alpha: float):
self._model = SGDClassifier(alpha=alpha)
def train(self, train_shard: ray.data.Dataset):
for i, epoch in enumerate(train_shard.iter_epochs()):
X, Y = zip(*list(epoch.iter_rows()))
self._model.partial_fit(X, Y, classes=[0, 1])
return self._model
def test(self, X_test: np.ndarray, Y_test: np.ndarray):
return self._model.score(X_test, Y_test)
from sklearn import datasets
from sklearn.linear_model import SGDClassifier
from sklearn.model_selection import train_test_split
@ray.remote
class TrainingWorker:
def __init__(self, alpha: float):
self._model = SGDClassifier(alpha=alpha)
def train(self, train_shard: ray.data.Dataset):
for i, epoch in enumerate(train_shard.iter_epochs()):
X, Y = zip(*list(epoch.iter_rows()))
self._model.partial_fit(X, Y, classes=[0, 1])
return self._model
def test(self, X_test: np.ndarray, Y_test: np.ndarray):
return self._model.score(X_test, Y_test)
In [ ]:
Copied!
ALPHA_VALS = [0.00008, 0.00009, 0.0001, 0.00011, 0.00012]
print(f"Starting {len(ALPHA_VALS)} training workers.")
workers = [TrainingWorker.remote(alpha) for alpha in ALPHA_VALS]
ALPHA_VALS = [0.00008, 0.00009, 0.0001, 0.00011, 0.00012]
print(f"Starting {len(ALPHA_VALS)} training workers.")
workers = [TrainingWorker.remote(alpha) for alpha in ALPHA_VALS]
In [ ]:
Copied!
X_train, X_test, Y_train, Y_test = train_test_split(
*datasets.make_classification()
)
train_ds = ray.data.from_items(list(zip(X_train, Y_train)))
shards = (train_ds.repeat(10)
.random_shuffle_each_window()
.split(len(workers), locality_hints=workers))
ray.get([worker.train.remote(shard) for worker, shard in zip(workers, shards)])
X_train, X_test, Y_train, Y_test = train_test_split(
*datasets.make_classification()
)
train_ds = ray.data.from_items(list(zip(X_train, Y_train)))
shards = (train_ds.repeat(10)
.random_shuffle_each_window()
.split(len(workers), locality_hints=workers))
ray.get([worker.train.remote(shard) for worker, shard in zip(workers, shards)])
In [ ]:
Copied!
# Get validation results from each worker.
print(ray.get([worker.test.remote(X_test, Y_test) for worker in workers]))
ray.shutdown()
# Get validation results from each worker.
print(ray.get([worker.test.remote(X_test, Y_test) for worker in workers]))
ray.shutdown()
In [ ]:
Copied!
import ray
from ray.util.dask import enable_dask_on_ray
ray.init() # Start or connect to Ray.
enable_dask_on_ray() # Enable the Ray scheduler backend for Dask.
import ray
from ray.util.dask import enable_dask_on_ray
ray.init() # Start or connect to Ray.
enable_dask_on_ray() # Enable the Ray scheduler backend for Dask.
In [ ]:
Copied!
import dask
df = dask.datasets.timeseries()
df = df[df.y > 0].groupby("name").x.std()
df.compute() # Trigger the task graph to be evaluated.
import dask
df = dask.datasets.timeseries()
df = df[df.y > 0].groupby("name").x.std()
df.compute() # Trigger the task graph to be evaluated.
In [ ]:
Copied!
import ray
ds = ray.data.range(10000)
# Convert the Dataset to a Dask DataFrame.
df = ds.to_dask()
print(df.std().compute()) # -> 2886.89568
# Convert the Dask DataFrame back to a Dataset.
ds = ray.data.from_dask(df)
print(ds.std()) # -> 2886.89568
import ray
ds = ray.data.range(10000)
# Convert the Dataset to a Dask DataFrame.
df = ds.to_dask()
print(df.std().compute()) # -> 2886.89568
# Convert the Dask DataFrame back to a Dataset.
ds = ray.data.from_dask(df)
print(ds.std()) # -> 2886.89568