Hyperparameter Optimization with Ray Tune¶
You can run this notebook directly in
Colab.
![]()
For this chapter you need to install the following dependencies:
In [ ]:
Copied!
! pip install "ray[tune]==2.2.0"
! pip install "hyperopt==0.2.7"
! pip install "bayesian-optimization==1.3.1"
! pip install "tensorflow>=2.9.0"
! pip install "ray[tune]==2.2.0"
! pip install "hyperopt==0.2.7"
! pip install "bayesian-optimization==1.3.1"
! pip install "tensorflow>=2.9.0"
To import utility files for this chapter, on Colab you will also have to clone the repo and copy the code files to the base path of the runtime:
In [ ]:
Copied!
!git clone https://github.com/maxpumperla/learning_ray
%cp -r learning_ray/notebooks/* .
!git clone https://github.com/maxpumperla/learning_ray
%cp -r learning_ray/notebooks/* .
In [ ]:
Copied!
from maze_gym_env import Environment
import time
import numpy as np
class Policy:
def __init__(self, env):
"""A Policy suggests actions based on the current state.
We do this by tracking the value of each state-action pair.
"""
self.state_action_table = [
[0 for _ in range(env.action_space.n)]
for _ in range(env.observation_space.n)
]
self.action_space = env.action_space
def get_action(self, state, explore=True, epsilon=0.1):
"""Explore randomly or exploit the best value currently available."""
if explore and random.uniform(0, 1) < epsilon:
return self.action_space.sample()
return np.argmax(self.state_action_table[state])
class Simulation(object):
def __init__(self, env):
"""Simulates rollouts of an environment, given a policy to follow."""
self.env = env
def rollout(self, policy, render=False, explore=True, epsilon=0.1):
"""Returns experiences for a policy rollout."""
experiences = []
state = self.env.reset()
done = False
while not done:
action = policy.get_action(state, explore, epsilon)
next_state, reward, done, info = self.env.step(action)
experiences.append([state, action, reward, next_state])
state = next_state
if render:
time.sleep(0.05)
self.env.render()
return experiences
def update_policy(policy, experiences, weight=0.1, discount_factor=0.9):
"""Updates a given policy with a list of (state, action, reward, state)
experiences."""
for state, action, reward, next_state in experiences:
next_max = np.max(policy.state_action_table[next_state])
value = policy.state_action_table[state][action]
new_value = (1 - weight) * value + weight * \
(reward + discount_factor * next_max)
policy.state_action_table[state][action] = new_value
def train_policy(env, num_episodes=10000, weight=0.1, discount_factor=0.9):
"""Training a policy by updating it with rollout experiences."""
policy = Policy(env)
sim = Simulation(env)
for _ in range(num_episodes):
experiences = sim.rollout(policy)
update_policy(policy, experiences, weight, discount_factor)
return policy
def evaluate_policy(env, policy, num_episodes=10):
"""Evaluate a trained policy through rollouts."""
simulation = Simulation(env)
steps = 0
for _ in range(num_episodes):
experiences = simulation.rollout(policy, render=True, explore=False)
steps += len(experiences)
print(f"{steps / num_episodes} steps on average "
f"for a total of {num_episodes} episodes.")
return steps / num_episodes
from maze_gym_env import Environment
import time
import numpy as np
class Policy:
def __init__(self, env):
"""A Policy suggests actions based on the current state.
We do this by tracking the value of each state-action pair.
"""
self.state_action_table = [
[0 for _ in range(env.action_space.n)]
for _ in range(env.observation_space.n)
]
self.action_space = env.action_space
def get_action(self, state, explore=True, epsilon=0.1):
"""Explore randomly or exploit the best value currently available."""
if explore and random.uniform(0, 1) < epsilon:
return self.action_space.sample()
return np.argmax(self.state_action_table[state])
class Simulation(object):
def __init__(self, env):
"""Simulates rollouts of an environment, given a policy to follow."""
self.env = env
def rollout(self, policy, render=False, explore=True, epsilon=0.1):
"""Returns experiences for a policy rollout."""
experiences = []
state = self.env.reset()
done = False
while not done:
action = policy.get_action(state, explore, epsilon)
next_state, reward, done, info = self.env.step(action)
experiences.append([state, action, reward, next_state])
state = next_state
if render:
time.sleep(0.05)
self.env.render()
return experiences
def update_policy(policy, experiences, weight=0.1, discount_factor=0.9):
"""Updates a given policy with a list of (state, action, reward, state)
experiences."""
for state, action, reward, next_state in experiences:
next_max = np.max(policy.state_action_table[next_state])
value = policy.state_action_table[state][action]
new_value = (1 - weight) * value + weight * \
(reward + discount_factor * next_max)
policy.state_action_table[state][action] = new_value
def train_policy(env, num_episodes=10000, weight=0.1, discount_factor=0.9):
"""Training a policy by updating it with rollout experiences."""
policy = Policy(env)
sim = Simulation(env)
for _ in range(num_episodes):
experiences = sim.rollout(policy)
update_policy(policy, experiences, weight, discount_factor)
return policy
def evaluate_policy(env, policy, num_episodes=10):
"""Evaluate a trained policy through rollouts."""
simulation = Simulation(env)
steps = 0
for _ in range(num_episodes):
experiences = simulation.rollout(policy, render=True, explore=False)
steps += len(experiences)
print(f"{steps / num_episodes} steps on average "
f"for a total of {num_episodes} episodes.")
return steps / num_episodes
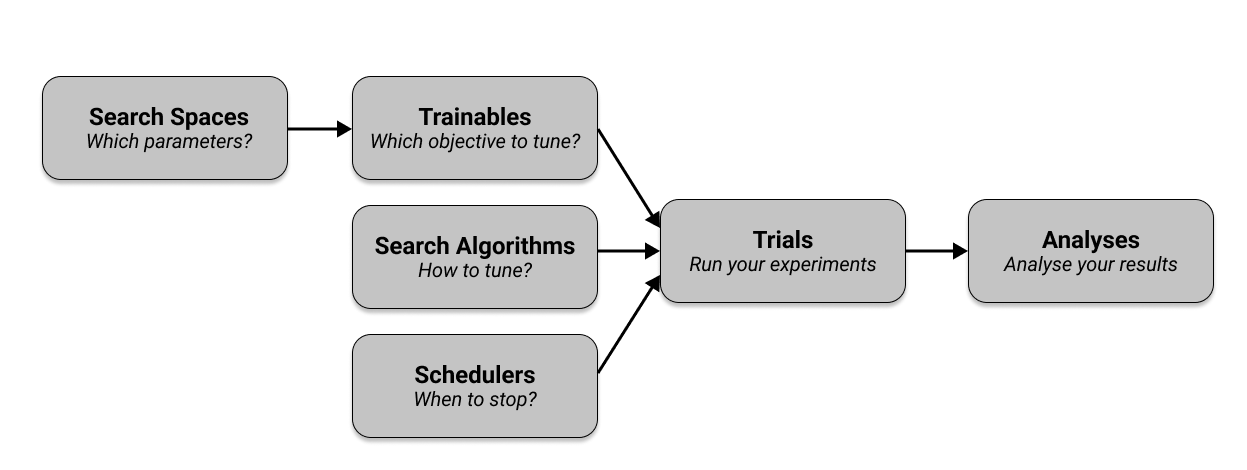
In [ ]:
Copied!
import random
search_space = []
for i in range(10):
random_choice = {
'weight': random.uniform(0, 1),
'discount_factor': random.uniform(0, 1)
}
search_space.append(random_choice)
import random
search_space = []
for i in range(10):
random_choice = {
'weight': random.uniform(0, 1),
'discount_factor': random.uniform(0, 1)
}
search_space.append(random_choice)
In [ ]:
Copied!
import ray
@ray.remote
def objective(config):
environment = Environment()
policy = train_policy(
environment,
weight=config["weight"],
discount_factor=config["discount_factor"]
)
score = evaluate_policy(environment, policy)
return [score, config]
import ray
@ray.remote
def objective(config):
environment = Environment()
policy = train_policy(
environment,
weight=config["weight"],
discount_factor=config["discount_factor"]
)
score = evaluate_policy(environment, policy)
return [score, config]
In [ ]:
Copied!
result_objects = [objective.remote(choice) for choice in search_space]
results = ray.get(result_objects)
results.sort(key=lambda x: x[0])
print(results[-1])
result_objects = [objective.remote(choice) for choice in search_space]
results = ray.get(result_objects)
results.sort(key=lambda x: x[0])
print(results[-1])
In [ ]:
Copied!
from ray import tune
search_space = {
"weight": tune.uniform(0, 1),
"discount_factor": tune.uniform(0, 1),
}
from ray import tune
search_space = {
"weight": tune.uniform(0, 1),
"discount_factor": tune.uniform(0, 1),
}
In [ ]:
Copied!
def tune_objective(config):
environment = Environment()
policy = train_policy(
environment,
weight=config["weight"],
discount_factor=config["discount_factor"]
)
score = evaluate_policy(environment, policy)
return {"score": score}
def tune_objective(config):
environment = Environment()
policy = train_policy(
environment,
weight=config["weight"],
discount_factor=config["discount_factor"]
)
score = evaluate_policy(environment, policy)
return {"score": score}
In [ ]:
Copied!
analysis = tune.run(tune_objective, config=search_space)
print(analysis.get_best_config(metric="score", mode="min"))
analysis = tune.run(tune_objective, config=search_space)
print(analysis.get_best_config(metric="score", mode="min"))
In [ ]:
Copied!
from ray.tune.suggest.bayesopt import BayesOptSearch
algo = BayesOptSearch(random_search_steps=4)
tune.run(
tune_objective,
config=search_space,
metric="score",
mode="min",
search_alg=algo,
stop={"training_iteration": 10},
)
from ray.tune.suggest.bayesopt import BayesOptSearch
algo = BayesOptSearch(random_search_steps=4)
tune.run(
tune_objective,
config=search_space,
metric="score",
mode="min",
search_alg=algo,
stop={"training_iteration": 10},
)
In [ ]:
Copied!
def objective(config):
for step in range(30):
score = config["weight"] * (step ** 0.5) + config["bias"]
tune.report(score=score)
search_space = {"weight": tune.uniform(0, 1), "bias": tune.uniform(0, 1)}
def objective(config):
for step in range(30):
score = config["weight"] * (step ** 0.5) + config["bias"]
tune.report(score=score)
search_space = {"weight": tune.uniform(0, 1), "bias": tune.uniform(0, 1)}
In [ ]:
Copied!
from ray.tune.schedulers import HyperBandScheduler
scheduler = HyperBandScheduler(metric="score", mode="min")
analysis = tune.run(
objective,
config=search_space,
scheduler=scheduler,
num_samples=10,
)
print(analysis.get_best_config(metric="score", mode="min"))
from ray.tune.schedulers import HyperBandScheduler
scheduler = HyperBandScheduler(metric="score", mode="min")
analysis = tune.run(
objective,
config=search_space,
scheduler=scheduler,
num_samples=10,
)
print(analysis.get_best_config(metric="score", mode="min"))
In [ ]:
Copied!
# NOTE: in the book we have 0.5 GPUs, but set this to 0 here so that it runs on Colab.
from ray import tune
tune.run(
objective,
config=search_space,
num_samples=10,
resources_per_trial={"cpu": 2, "gpu": 0}
)
# NOTE: in the book we have 0.5 GPUs, but set this to 0 here so that it runs on Colab.
from ray import tune
tune.run(
objective,
config=search_space,
num_samples=10,
resources_per_trial={"cpu": 2, "gpu": 0}
)
In [ ]:
Copied!
from ray import tune
from ray.tune import Callback
from ray.tune.logger import pretty_print
class PrintResultCallback(Callback):
def on_trial_result(self, iteration, trials, trial, result, **info):
print(f"Trial {trial} in iteration {iteration}, "
f"got result: {result['score']}")
def objective(config):
for step in range(30):
score = config["weight"] * (step ** 0.5) + config["bias"]
tune.report(score=score, step=step, more_metrics={})
from ray import tune
from ray.tune import Callback
from ray.tune.logger import pretty_print
class PrintResultCallback(Callback):
def on_trial_result(self, iteration, trials, trial, result, **info):
print(f"Trial {trial} in iteration {iteration}, "
f"got result: {result['score']}")
def objective(config):
for step in range(30):
score = config["weight"] * (step ** 0.5) + config["bias"]
tune.report(score=score, step=step, more_metrics={})
In [ ]:
Copied!
search_space = {"weight": tune.uniform(0, 1), "bias": tune.uniform(0, 1)}
analysis = tune.run(
objective,
config=search_space,
mode="min",
metric="score",
callbacks=[PrintResultCallback()])
best = analysis.best_trial
print(pretty_print(best.last_result))
search_space = {"weight": tune.uniform(0, 1), "bias": tune.uniform(0, 1)}
analysis = tune.run(
objective,
config=search_space,
mode="min",
metric="score",
callbacks=[PrintResultCallback()])
best = analysis.best_trial
print(pretty_print(best.last_result))
In [ ]:
Copied!
# NOTE: this will only run if you insert a correct logdir.
analysis = tune.run(
objective,
name="<your-logdir>",
resume=True,
config=search_space)
# NOTE: this will only run if you insert a correct logdir.
analysis = tune.run(
objective,
name="",
resume=True,
config=search_space)
In [ ]:
Copied!
tune.run(
objective,
config=search_space,
stop={"training_iteration": 10})
tune.run(
objective,
config=search_space,
stop={"training_iteration": 10})
In [ ]:
Copied!
def stopper(trial_id, result):
return result["score"] < 2
tune.run(
objective,
config=search_space,
stop=stopper)
def stopper(trial_id, result):
return result["score"] < 2
tune.run(
objective,
config=search_space,
stop=stopper)
In [ ]:
Copied!
from ray import tune
import numpy as np
search_space = {
"weight": tune.sample_from(
lambda context: np.random.uniform(low=0.0, high=1.0)
),
"bias": tune.sample_from(
lambda context: context.config.weight * np.random.normal()
)}
tune.run(objective, config=search_space)
from ray import tune
import numpy as np
search_space = {
"weight": tune.sample_from(
lambda context: np.random.uniform(low=0.0, high=1.0)
),
"bias": tune.sample_from(
lambda context: context.config.weight * np.random.normal()
)}
tune.run(objective, config=search_space)
In [ ]:
Copied!
# NOTE: this run will take incredibly long on Colab, be warned!
from ray import tune
analysis = tune.run(
"DQN",
metric="episode_reward_mean",
mode="max",
config={
"env": "CartPole-v1",
"lr": tune.uniform(1e-5, 1e-4),
"train_batch_size": tune.choice([10000, 20000, 40000]),
},
)
# NOTE: this run will take incredibly long on Colab, be warned!
from ray import tune
analysis = tune.run(
"DQN",
metric="episode_reward_mean",
mode="max",
config={
"env": "CartPole-v1",
"lr": tune.uniform(1e-5, 1e-4),
"train_batch_size": tune.choice([10000, 20000, 40000]),
},
)
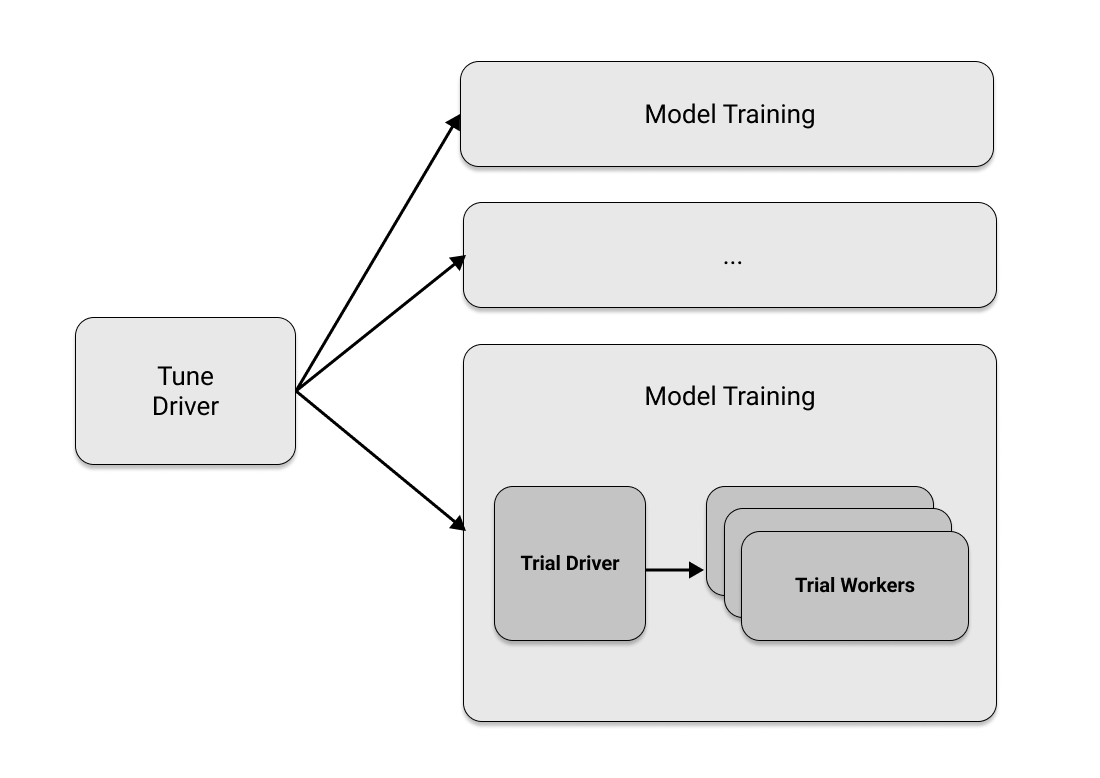
In [ ]:
Copied!
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
def load_data():
(x_train, y_train), (x_test, y_test) = mnist.load_data()
num_classes = 10
x_train, x_test = x_train / 255.0, x_test / 255.0
y_train = to_categorical(y_train, num_classes)
y_test = to_categorical(y_test, num_classes)
return (x_train, y_train), (x_test, y_test)
load_data()
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
def load_data():
(x_train, y_train), (x_test, y_test) = mnist.load_data()
num_classes = 10
x_train, x_test = x_train / 255.0, x_test / 255.0
y_train = to_categorical(y_train, num_classes)
y_test = to_categorical(y_test, num_classes)
return (x_train, y_train), (x_test, y_test)
load_data()
In [ ]:
Copied!
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense, Dropout
from ray.tune.integration.keras import TuneReportCallback
def objective(config):
(x_train, y_train), (x_test, y_test) = load_data()
model = Sequential()
model.add(Flatten(input_shape=(28, 28)))
model.add(Dense(config["hidden"], activation=config["activation"]))
model.add(Dropout(config["rate"]))
model.add(Dense(10, activation="softmax"))
model.compile(loss="categorical_crossentropy", metrics=["accuracy"])
model.fit(x_train, y_train, batch_size=128, epochs=10,
validation_data=(x_test, y_test),
callbacks=[TuneReportCallback({"mean_accuracy": "accuracy"})])
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense, Dropout
from ray.tune.integration.keras import TuneReportCallback
def objective(config):
(x_train, y_train), (x_test, y_test) = load_data()
model = Sequential()
model.add(Flatten(input_shape=(28, 28)))
model.add(Dense(config["hidden"], activation=config["activation"]))
model.add(Dropout(config["rate"]))
model.add(Dense(10, activation="softmax"))
model.compile(loss="categorical_crossentropy", metrics=["accuracy"])
model.fit(x_train, y_train, batch_size=128, epochs=10,
validation_data=(x_test, y_test),
callbacks=[TuneReportCallback({"mean_accuracy": "accuracy"})])
In [ ]:
Copied!
from ray import tune
from ray.tune.suggest.hyperopt import HyperOptSearch
initial_params = [{"rate": 0.2, "hidden": 128, "activation": "relu"}]
algo = HyperOptSearch(points_to_evaluate=initial_params)
search_space = {
"rate": tune.uniform(0.1, 0.5),
"hidden": tune.randint(32, 512),
"activation": tune.choice(["relu", "tanh"])
}
analysis = tune.run(
objective,
name="keras_hyperopt_exp",
search_alg=algo,
metric="mean_accuracy",
mode="max",
stop={"mean_accuracy": 0.99},
num_samples=10,
config=search_space,
)
print("Best hyperparameters found were: ", analysis.best_config)
from ray import tune
from ray.tune.suggest.hyperopt import HyperOptSearch
initial_params = [{"rate": 0.2, "hidden": 128, "activation": "relu"}]
algo = HyperOptSearch(points_to_evaluate=initial_params)
search_space = {
"rate": tune.uniform(0.1, 0.5),
"hidden": tune.randint(32, 512),
"activation": tune.choice(["relu", "tanh"])
}
analysis = tune.run(
objective,
name="keras_hyperopt_exp",
search_alg=algo,
metric="mean_accuracy",
mode="max",
stop={"mean_accuracy": 0.99},
num_samples=10,
config=search_space,
)
print("Best hyperparameters found were: ", analysis.best_config)