Reinforcement Learning with Ray RLlib¶
You can run this notebook directly in
Colab.
![]()
For this chapter you need to install the following dependencies:
In [ ]:
Copied!
! pip install "ray[rllib]==2.2.0"
! pip install "ray[rllib]==2.2.0"
To import utility files for this chapter, on Colab you will also have to clone the repo and copy the code files to the base path of the runtime:
In [ ]:
Copied!
!git clone https://github.com/maxpumperla/learning_ray
%cp -r learning_ray/notebooks/* .
!git clone https://github.com/maxpumperla/learning_ray
%cp -r learning_ray/notebooks/* .
In [ ]:
Copied!
import gym
class Env:
action_space: gym.spaces.Space
observation_space: gym.spaces.Space
def step(self, action):
...
def reset(self):
...
def render(self, mode="human"):
...
import gym
class Env:
action_space: gym.spaces.Space
observation_space: gym.spaces.Space
def step(self, action):
...
def reset(self):
...
def render(self, mode="human"):
...
In maze.py we set num_rollout_workers=0 for this notebook, so that the code works in Colab. In the book itself we use 2 rollout workers to show that experience collection can be distributed by RLlib.
In [ ]:
Copied!
! rllib train file maze.py --stop '{"timesteps_total": 10000}'
! rllib train file maze.py --stop '{"timesteps_total": 10000}'
Try:
rllib evaluate ~/ray_results/maze_env/
In [ ]:
Copied!
from ray.tune.logger import pretty_print
from maze_gym_env import GymEnvironment
from ray.rllib.algorithms.dqn import DQNConfig
config = (DQNConfig().environment(GymEnvironment)
.rollouts(num_rollout_workers=2, create_env_on_local_worker=True))
pretty_print(config.to_dict())
algo = config.build()
for i in range(10):
result = algo.train()
print(pretty_print(result))
from ray.tune.logger import pretty_print
from maze_gym_env import GymEnvironment
from ray.rllib.algorithms.dqn import DQNConfig
config = (DQNConfig().environment(GymEnvironment)
.rollouts(num_rollout_workers=2, create_env_on_local_worker=True))
pretty_print(config.to_dict())
algo = config.build()
for i in range(10):
result = algo.train()
print(pretty_print(result))
In [ ]:
Copied!
from ray.rllib.algorithms.algorithm import Algorithm
checkpoint = algo.save()
print(checkpoint)
evaluation = algo.evaluate()
print(pretty_print(evaluation))
algo.stop()
restored_algo = Algorithm.from_checkpoint(checkpoint)
algo = restored_algo
from ray.rllib.algorithms.algorithm import Algorithm
checkpoint = algo.save()
print(checkpoint)
evaluation = algo.evaluate()
print(pretty_print(evaluation))
algo.stop()
restored_algo = Algorithm.from_checkpoint(checkpoint)
algo = restored_algo
In [ ]:
Copied!
env = GymEnvironment()
done = False
total_reward = 0
observations = env.reset()
while not done:
action = algo.compute_single_action(observations)
observations, reward, done, info = env.step(action)
total_reward += reward
env = GymEnvironment()
done = False
total_reward = 0
observations = env.reset()
while not done:
action = algo.compute_single_action(observations)
observations, reward, done, info = env.step(action)
total_reward += reward
In [ ]:
Copied!
action = algo.compute_actions(
{"obs_1": observations, "obs_2": observations}
)
print(action)
# {'obs_1': 0, 'obs_2': 1}
action = algo.compute_actions(
{"obs_1": observations, "obs_2": observations}
)
print(action)
# {'obs_1': 0, 'obs_2': 1}
In [ ]:
Copied!
policy = algo.get_policy()
print(policy.get_weights())
model = policy.model
policy = algo.get_policy()
print(policy.get_weights())
model = policy.model
In [ ]:
Copied!
workers = algo.workers
workers.foreach_worker(
lambda remote_trainer: remote_trainer.get_policy().get_weights()
)
workers = algo.workers
workers.foreach_worker(
lambda remote_trainer: remote_trainer.get_policy().get_weights()
)
In [ ]:
Copied!
model.base_model.summary()
model.base_model.summary()
In [ ]:
Copied!
from ray.rllib.models.preprocessors import get_preprocessor
env = GymEnvironment()
obs_space = env.observation_space
preprocessor = get_preprocessor(obs_space)(obs_space)
observations = env.reset()
transformed = preprocessor.transform(observations).reshape(1, -1)
model_output, _ = model({"obs": transformed})
from ray.rllib.models.preprocessors import get_preprocessor
env = GymEnvironment()
obs_space = env.observation_space
preprocessor = get_preprocessor(obs_space)(obs_space)
observations = env.reset()
transformed = preprocessor.transform(observations).reshape(1, -1)
model_output, _ = model({"obs": transformed})
In [ ]:
Copied!
q_values = model.get_q_value_distributions(model_output)
print(q_values)
action_distribution = policy.dist_class(model_output, model)
sample = action_distribution.sample()
print(sample)
q_values = model.get_q_value_distributions(model_output)
print(q_values)
action_distribution = policy.dist_class(model_output, model)
sample = action_distribution.sample()
print(sample)
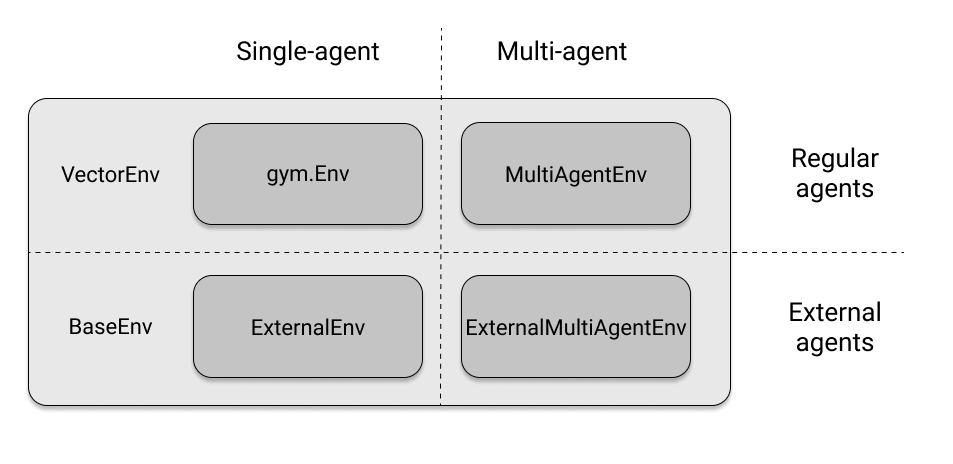
In [ ]:
Copied!
from ray.rllib.env.multi_agent_env import MultiAgentEnv
from gym.spaces import Discrete
import os
class MultiAgentMaze(MultiAgentEnv):
def __init__(self, *args, **kwargs):
self.action_space = Discrete(4)
self.observation_space = Discrete(5*5)
self.agents = {1: (4, 0), 2: (0, 4)}
self.goal = (4, 4)
self.info = {1: {'obs': self.agents[1]}, 2: {'obs': self.agents[2]}}
def reset(self):
self.agents = {1: (4, 0), 2: (0, 4)}
return {1: self.get_observation(1), 2: self.get_observation(2)}
def get_observation(self, agent_id):
seeker = self.agents[agent_id]
return 5 * seeker[0] + seeker[1]
def get_reward(self, agent_id):
return 1 if self.agents[agent_id] == self.goal else 0
def is_done(self, agent_id):
return self.agents[agent_id] == self.goal
def step(self, action):
agent_ids = action.keys()
for agent_id in agent_ids:
seeker = self.agents[agent_id]
if action[agent_id] == 0: # move down
seeker = (min(seeker[0] + 1, 4), seeker[1])
elif action[agent_id] == 1: # move left
seeker = (seeker[0], max(seeker[1] - 1, 0))
elif action[agent_id] == 2: # move up
seeker = (max(seeker[0] - 1, 0), seeker[1])
elif action[agent_id] == 3: # move right
seeker = (seeker[0], min(seeker[1] + 1, 4))
else:
raise ValueError("Invalid action")
self.agents[agent_id] = seeker
observations = {i: self.get_observation(i) for i in agent_ids}
rewards = {i: self.get_reward(i) for i in agent_ids}
done = {i: self.is_done(i) for i in agent_ids}
done["__all__"] = all(done.values())
return observations, rewards, done, self.info
def render(self, *args, **kwargs):
"""We override this method here so clear the output in Jupyter notebooks.
The previous implementation works well in the terminal, but does not clear
the screen in interactive environments.
"""
os.system('cls' if os.name == 'nt' else 'clear')
try:
from IPython.display import clear_output
clear_output(wait=True)
except Exception:
pass
grid = [['| ' for _ in range(5)] + ["|\n"] for _ in range(5)]
grid[self.goal[0]][self.goal[1]] = '|G'
grid[self.agents[1][0]][self.agents[1][1]] = '|1'
grid[self.agents[2][0]][self.agents[2][1]] = '|2'
grid[self.agents[2][0]][self.agents[2][1]] = '|2'
print(''.join([''.join(grid_row) for grid_row in grid]))
from ray.rllib.env.multi_agent_env import MultiAgentEnv
from gym.spaces import Discrete
import os
class MultiAgentMaze(MultiAgentEnv):
def __init__(self, *args, **kwargs):
self.action_space = Discrete(4)
self.observation_space = Discrete(5*5)
self.agents = {1: (4, 0), 2: (0, 4)}
self.goal = (4, 4)
self.info = {1: {'obs': self.agents[1]}, 2: {'obs': self.agents[2]}}
def reset(self):
self.agents = {1: (4, 0), 2: (0, 4)}
return {1: self.get_observation(1), 2: self.get_observation(2)}
def get_observation(self, agent_id):
seeker = self.agents[agent_id]
return 5 * seeker[0] + seeker[1]
def get_reward(self, agent_id):
return 1 if self.agents[agent_id] == self.goal else 0
def is_done(self, agent_id):
return self.agents[agent_id] == self.goal
def step(self, action):
agent_ids = action.keys()
for agent_id in agent_ids:
seeker = self.agents[agent_id]
if action[agent_id] == 0: # move down
seeker = (min(seeker[0] + 1, 4), seeker[1])
elif action[agent_id] == 1: # move left
seeker = (seeker[0], max(seeker[1] - 1, 0))
elif action[agent_id] == 2: # move up
seeker = (max(seeker[0] - 1, 0), seeker[1])
elif action[agent_id] == 3: # move right
seeker = (seeker[0], min(seeker[1] + 1, 4))
else:
raise ValueError("Invalid action")
self.agents[agent_id] = seeker
observations = {i: self.get_observation(i) for i in agent_ids}
rewards = {i: self.get_reward(i) for i in agent_ids}
done = {i: self.is_done(i) for i in agent_ids}
done["__all__"] = all(done.values())
return observations, rewards, done, self.info
def render(self, *args, **kwargs):
"""We override this method here so clear the output in Jupyter notebooks.
The previous implementation works well in the terminal, but does not clear
the screen in interactive environments.
"""
os.system('cls' if os.name == 'nt' else 'clear')
try:
from IPython.display import clear_output
clear_output(wait=True)
except Exception:
pass
grid = [['| ' for _ in range(5)] + ["|\n"] for _ in range(5)]
grid[self.goal[0]][self.goal[1]] = '|G'
grid[self.agents[1][0]][self.agents[1][1]] = '|1'
grid[self.agents[2][0]][self.agents[2][1]] = '|2'
grid[self.agents[2][0]][self.agents[2][1]] = '|2'
print(''.join([''.join(grid_row) for grid_row in grid]))
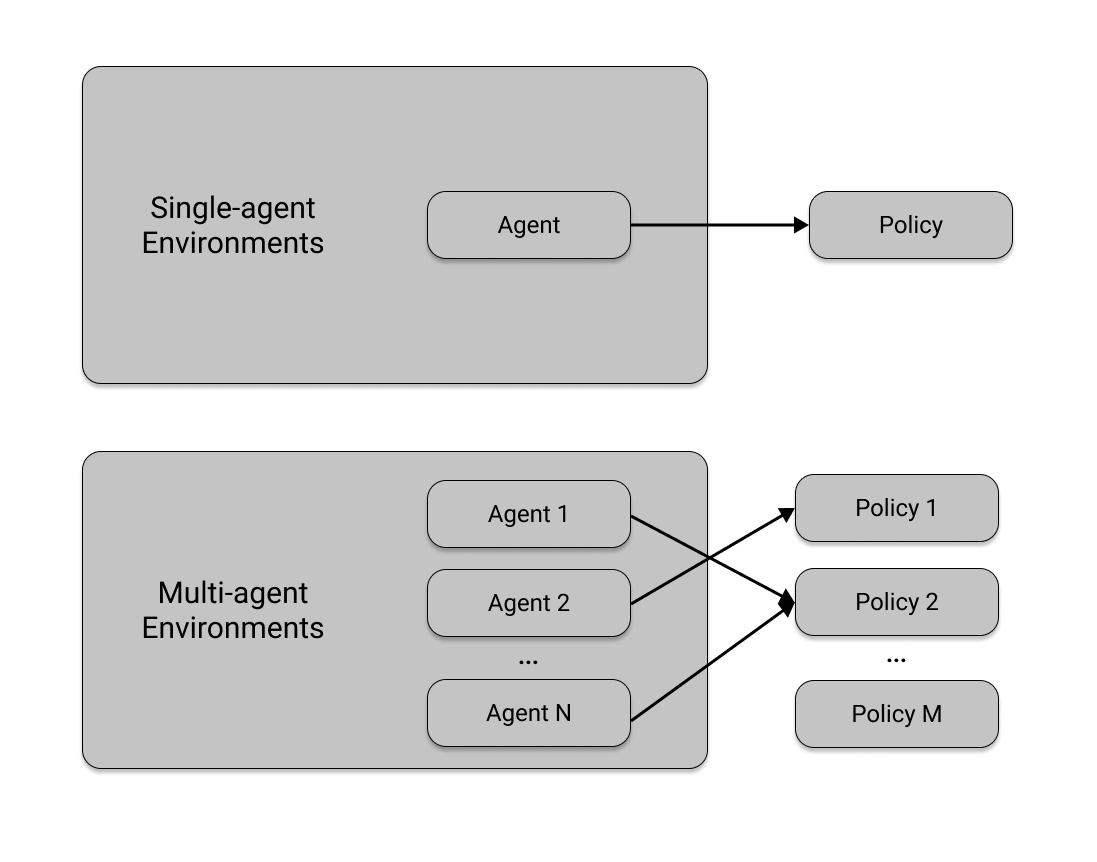
In [ ]:
Copied!
import time
env = MultiAgentMaze()
while True:
obs, rew, done, info = env.step(
{1: env.action_space.sample(), 2: env.action_space.sample()}
)
time.sleep(0.1)
env.render()
if any(done.values()):
break
import time
env = MultiAgentMaze()
while True:
obs, rew, done, info = env.step(
{1: env.action_space.sample(), 2: env.action_space.sample()}
)
time.sleep(0.1)
env.render()
if any(done.values()):
break
In [ ]:
Copied!
from ray.rllib.algorithms.dqn import DQNConfig
simple_trainer = DQNConfig().environment(env=MultiAgentMaze).build()
simple_trainer.train()
algo = DQNConfig()\
.environment(env=MultiAgentMaze)\
.multi_agent(
policies={
"policy_1": (
None, env.observation_space, env.action_space, {"gamma": 0.80}
),
"policy_2": (
None, env.observation_space, env.action_space, {"gamma": 0.95}
),
},
policy_mapping_fn = lambda agent_id: f"policy_{agent_id}",
).build()
print(algo.train())
from ray.rllib.algorithms.dqn import DQNConfig
simple_trainer = DQNConfig().environment(env=MultiAgentMaze).build()
simple_trainer.train()
algo = DQNConfig()\
.environment(env=MultiAgentMaze)\
.multi_agent(
policies={
"policy_1": (
None, env.observation_space, env.action_space, {"gamma": 0.80}
),
"policy_2": (
None, env.observation_space, env.action_space, {"gamma": 0.95}
),
},
policy_mapping_fn = lambda agent_id: f"policy_{agent_id}",
).build()
print(algo.train())
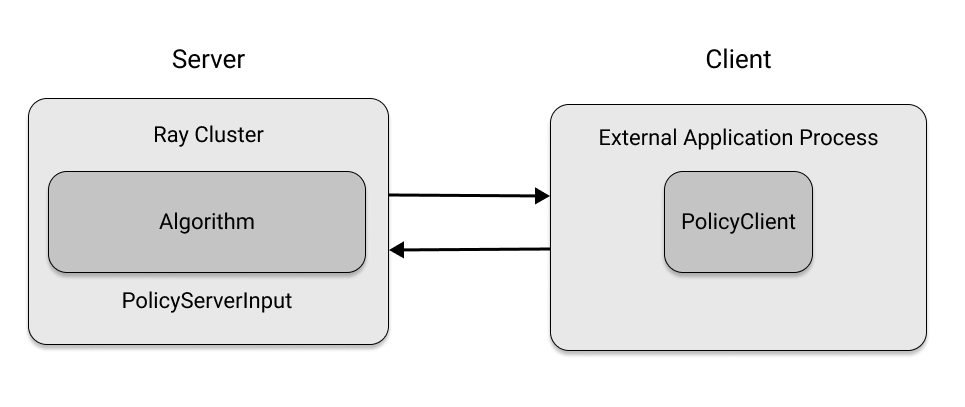
In [ ]:
Copied!
from gym.spaces import Discrete
import random
import os
class AdvancedEnv(GymEnvironment):
def __init__(self, seeker=None, *args, **kwargs):
super().__init__(*args, **kwargs)
self.maze_len = 11
self.action_space = Discrete(4)
self.observation_space = Discrete(self.maze_len * self.maze_len)
if seeker:
assert 0 <= seeker[0] < self.maze_len and \
0 <= seeker[1] < self.maze_len
self.seeker = seeker
else:
self.reset()
self.goal = (self.maze_len-1, self.maze_len-1)
self.info = {'seeker': self.seeker, 'goal': self.goal}
self.punish_states = [
(i, j) for i in range(self.maze_len) for j in range(self.maze_len)
if i % 2 == 1 and j % 2 == 0
]
def reset(self):
"""Reset seeker position randomly, return observations."""
self.seeker = (
random.randint(0, self.maze_len - 1),
random.randint(0, self.maze_len - 1)
)
return self.get_observation()
def get_observation(self):
"""Encode the seeker position as integer"""
return self.maze_len * self.seeker[0] + self.seeker[1]
def get_reward(self):
"""Reward finding the goal and punish forbidden states"""
reward = -1 if self.seeker in self.punish_states else 0
reward += 5 if self.seeker == self.goal else 0
return reward
def render(self, *args, **kwargs):
"""We override this method here so clear the output in Jupyter notebooks.
The previous implementation works well in the terminal, but does not clear
the screen in interactive environments.
"""
os.system('cls' if os.name == 'nt' else 'clear')
try:
from IPython.display import clear_output
clear_output(wait=True)
except Exception:
pass
grid = [['| ' for _ in range(self.maze_len)] +
["|\n"] for _ in range(self.maze_len)]
for punish in self.punish_states:
grid[punish[0]][punish[1]] = '|X'
grid[self.goal[0]][self.goal[1]] = '|G'
grid[self.seeker[0]][self.seeker[1]] = '|S'
print(''.join([''.join(grid_row) for grid_row in grid]))
from gym.spaces import Discrete
import random
import os
class AdvancedEnv(GymEnvironment):
def __init__(self, seeker=None, *args, **kwargs):
super().__init__(*args, **kwargs)
self.maze_len = 11
self.action_space = Discrete(4)
self.observation_space = Discrete(self.maze_len * self.maze_len)
if seeker:
assert 0 <= seeker[0] < self.maze_len and \
0 <= seeker[1] < self.maze_len
self.seeker = seeker
else:
self.reset()
self.goal = (self.maze_len-1, self.maze_len-1)
self.info = {'seeker': self.seeker, 'goal': self.goal}
self.punish_states = [
(i, j) for i in range(self.maze_len) for j in range(self.maze_len)
if i % 2 == 1 and j % 2 == 0
]
def reset(self):
"""Reset seeker position randomly, return observations."""
self.seeker = (
random.randint(0, self.maze_len - 1),
random.randint(0, self.maze_len - 1)
)
return self.get_observation()
def get_observation(self):
"""Encode the seeker position as integer"""
return self.maze_len * self.seeker[0] + self.seeker[1]
def get_reward(self):
"""Reward finding the goal and punish forbidden states"""
reward = -1 if self.seeker in self.punish_states else 0
reward += 5 if self.seeker == self.goal else 0
return reward
def render(self, *args, **kwargs):
"""We override this method here so clear the output in Jupyter notebooks.
The previous implementation works well in the terminal, but does not clear
the screen in interactive environments.
"""
os.system('cls' if os.name == 'nt' else 'clear')
try:
from IPython.display import clear_output
clear_output(wait=True)
except Exception:
pass
grid = [['| ' for _ in range(self.maze_len)] +
["|\n"] for _ in range(self.maze_len)]
for punish in self.punish_states:
grid[punish[0]][punish[1]] = '|X'
grid[self.goal[0]][self.goal[1]] = '|G'
grid[self.seeker[0]][self.seeker[1]] = '|S'
print(''.join([''.join(grid_row) for grid_row in grid]))
In [ ]:
Copied!
from ray.rllib.env.apis.task_settable_env import TaskSettableEnv
class CurriculumEnv(AdvancedEnv, TaskSettableEnv):
def __init__(self, *args, **kwargs):
AdvancedEnv.__init__(self)
def difficulty(self):
return abs(self.seeker[0] - self.goal[0]) + \
abs(self.seeker[1] - self.goal[1])
def get_task(self):
return self.difficulty()
def set_task(self, task_difficulty):
while not self.difficulty() <= task_difficulty:
self.reset()
from ray.rllib.env.apis.task_settable_env import TaskSettableEnv
class CurriculumEnv(AdvancedEnv, TaskSettableEnv):
def __init__(self, *args, **kwargs):
AdvancedEnv.__init__(self)
def difficulty(self):
return abs(self.seeker[0] - self.goal[0]) + \
abs(self.seeker[1] - self.goal[1])
def get_task(self):
return self.difficulty()
def set_task(self, task_difficulty):
while not self.difficulty() <= task_difficulty:
self.reset()
In [ ]:
Copied!
def curriculum_fn(train_results, task_settable_env, env_ctx):
time_steps = train_results.get("timesteps_total")
difficulty = time_steps // 1000
print(f"Current difficulty: {difficulty}")
return difficulty
def curriculum_fn(train_results, task_settable_env, env_ctx):
time_steps = train_results.get("timesteps_total")
difficulty = time_steps // 1000
print(f"Current difficulty: {difficulty}")
return difficulty
In [ ]:
Copied!
from ray.rllib.algorithms.dqn import DQNConfig
import tempfile
temp = tempfile.mkdtemp()
trainer = (
DQNConfig()
.environment(env=CurriculumEnv, env_task_fn=curriculum_fn)
.offline_data(output=temp)
.build()
)
for i in range(15):
trainer.train()
from ray.rllib.algorithms.dqn import DQNConfig
import tempfile
temp = tempfile.mkdtemp()
trainer = (
DQNConfig()
.environment(env=CurriculumEnv, env_task_fn=curriculum_fn)
.offline_data(output=temp)
.build()
)
for i in range(15):
trainer.train()
In [ ]:
Copied!
imitation_algo = (
DQNConfig()
.environment(env=AdvancedEnv)
.evaluation(off_policy_estimation_methods={})
.offline_data(input_=temp)
.exploration(explore=False)
.build())
for i in range(10):
imitation_algo.train()
imitation_algo.evaluate()
imitation_algo = (
DQNConfig()
.environment(env=AdvancedEnv)
.evaluation(off_policy_estimation_methods={})
.offline_data(input_=temp)
.exploration(explore=False)
.build())
for i in range(10):
imitation_algo.train()
imitation_algo.evaluate()