Getting Started with Ray Core¶
Many of Ray’s concepts can be explained with a good example, so that’s exactly what
we’ll do. As before, you can follow this example by typing the code yourself (which
is highly recommended), or by following the notebook for this chapter. You can run this notebook directly in
Colab:
![]()
In any case, make sure you have Ray installed:
! pip install "ray==2.2.0"
A Ray Core Intro¶
In Chapter 1 we showed you how start a local cluster simply by calling import ray
and then initializing it with ray.init(). After running this code you will see output
of the following form. We omit a lot of information in this example output, as that
would require you to understand more of Ray’s internals first.
... INFO services.py:1263 -- View the Ray dashboard at http://127.0.0.1:8265
{'node_ip_address': '192.168.1.41',
...
'node_id': '...'}The output of this command indicates that your Ray cluster is functioning properly. As shown in the first line of the output, Ray includes its own dashboard that can be accessed at http://127.0.0.1:8265 (unless a different port is listed in the output). You can take some time to explore the dashboard, which will display information such as the number of CPU cores available and the total utilization of your current Ray application. If you want to see the resource utilization of your Ray cluster within a Python script, you can use the ray.cluster_resources() function. On my computer, this function returns the following output:
{'CPU': 12.0,
'memory': 14203886388.0,
'node:127.0.0.1': 1.0,
'object_store_memory': 2147483648.0}To use the examples in this chapter, you will need to have a running Ray cluster. The purpose of this section is to give you a brief introduction to the Ray Core API, which we will refer to as the Ray API from now on. One of the great things about the Ray API for Python programmers is that it feels very familiar, using concepts such as decorators, functions, and classes. The Ray API is designed to provide a universal programming interface for distributed computing, which is a challenging task, but I believe that Ray succeeds in this by providing abstractions that are easy to understand and use. The Ray engine handles the complicated work behind the scenes, allowing Ray to be used with existing Python libraries and systems.
This chapter begins with a focus on Ray Core because we believe it has the potential to greatly enhance the ease of access to distributed computing. The purpose of this chapter is to give you an in-depth understanding of how Ray functions effectively and how you can grasp its basic concepts. It is important to note that if you are a Python programmer with less experience or prefer to concentrate on more advanced tasks, it may take some time to become familiar with Ray Core. However, we highly recommend taking the time to learn the Ray Core API as it is a fantastic way to start working with distributed computing using Python.
Your First Ray API Example¶
To give you an example, take the following function which retrieves and processes
data from a database. Our dummy database is a plain Python list containing the
words of the title of this book. To simulate the idea that accessing and processing data from the database is costly, we have the function sleep (pause for a certain amount of time) in Python.
import time
database = [
"Learning", "Ray",
"Flexible", "Distributed", "Python", "for", "Machine", "Learning"
]
def retrieve(item):
time.sleep(item / 10.)
return item, database[item]
Our database has eight items in total. If we were to retrieve all items sequentially, how
long should that take? For the item with index 5 we wait for half a second (5 / 10.)
and so on. In total, we can expect a runtime of around (0+1+2+3+4+5+6+7)/10. =
2.8 seconds. Let’s see if that’s what we actually get:
def print_runtime(input_data, start_time):
print(f'Runtime: {time.time() - start_time:.2f} seconds, data:')
print(*input_data, sep="\n")
start = time.time()
data = [retrieve(item) for item in range(8)]
print_runtime(data, start)
Runtime: 2.82 seconds, data: (0, 'Learning') (1, 'Ray') (2, 'Flexible') (3, 'Distributed') (4, 'Python') (5, 'for') (6, 'Machine') (7, 'Learning')
The total time it takes to run the function is 2.82 seconds, but this may vary on your individual computer. It's important to note that our basic Python version is not capable of running this function simultaneously.
You may not have been surprised to hear this, but it's likely that you at least suspected that Python list comprehensions are more efficient in terms of performance. The runtime we measured, which was 2.8 seconds, is actually the worst case scenario. It may be frustrating to see that a program that mostly just "sleeps" during its runtime could still be so slow, but the reason for this is due to the Global Interpreter Lock (GIL), which gets enough criticism as it is.
Ray Tasks¶
It’s reasonable to assume that such a task can benefit from parallelization. Perfectly distributed, the runtime should not take much longer than the longest subtask, namely 7/10. = 0.7 seconds. So, let’s see how you can extend this example to run on Ray. To do so, you start by using the @ray.remote decorator
import ray
@ray.remote
def retrieve_task(item):
return retrieve(item)
In this way, the function retrieve_task becomes a so-called Ray task. In essence, a Ray task is a function that gets executed on a different process that it was called from, potentially on a different machine.
It is very convenient to use Ray because you can continue to write your Python code as usual, without having to significantly change your approach or programming style. Using the @ray.remote decorator on your retrieve function is the intended use of decorators, but for the purpose of clarity, we did not modify the original code in this example.
To retrieve database entries and measure performance, what changes do you need to make to the code? It's actually not a lot. Here's an overview of the process:
start = time.time()
object_references = [
retrieve_task.remote(item) for item in range(8)
]
data = ray.get(object_references)
print_runtime(data, start)
2022-12-20 13:52:34,632 INFO worker.py:1529 -- Started a local Ray instance. View the dashboard at 127.0.0.1:8265
Runtime: 4.54 seconds, data: (0, 'Learning') (1, 'Ray') (2, 'Flexible') (3, 'Distributed') (4, 'Python') (5, 'for') (6, 'Machine') (7, 'Learning')
Have you noticed the differences? To execute your Ray task remotely, you must use a .remote() call. When tasks are executed remotely, even on your local cluster, Ray does it asynchronously. The items in the object_references list in the previous code snippet do not directly contain the results. In fact, if you check the Python type of the first item using type(object_references[0]), you will see that it is actually an ObjectRef. These object references correspond to futures that you need to request the result of. This is what the call to ray.get(...) is for. Whenever you call remote on a Ray task, it will immediately return one or more object references. In reality, while we introduced ray.put(...) first, you should consider Ray tasks as the primary way of creating objects. In the following section, we will provide an example that links multiple tasks together and allows Ray to handle passing and resolving the objects between them.
We still wish to continue working on this example, but let's take a moment to review what we have done so far. You began with a Python function and decorated it with @ray.remote, which made the function a Ray task. Instead of directly calling the original function in your code, you called .remote(...) on the Ray task. The final step was to retrieve the results back from your Ray cluster using .get(...). I believe this process is so straightforward that I would bet you could create your own Ray task from another function without referring back to this example. Why don't you give it a try now?
Coming back to our example, by using Ray tasks, what did we gain in terms of performance? On my machine the runtime clocks in at 0.71 seconds, which is just slightly more than the longest subtask, which comes in at 0.7 seconds. That’s great and much better than before, but we can further improve our program by leveraging more of Ray’s API.
The Object Store¶
One aspect that may have been noticed is that the retrieve definition involves directly accessing items from the database. While this works well on a local Ray cluster, it is important to consider how this would function on an actual cluster with multiple computers. In a Ray cluster, there is a head node with a driver process and multiple worker nodes with worker processes executing tasks. By default, Ray creates as many worker processes as there are CPU cores on the machine. However, in this scenario the database is defined on the driver only, but the worker processes need access to it to run the retrieve task. Fortunately, Ray has a simple solution for sharing objects between the driver and workers or between workers - using the put function to place the data into Ray's distributed object store. In the retrieve_task definition, we explicitly include a db argument, which will later be passed the db_object_ref object.
db_object_ref = ray.put(database)
@ray.remote
def retrieve_task(item, db):
time.sleep(item / 10.)
return item, db[item]
By utilizing the object store in this manner, you can allow Ray to manage data access throughout the entire cluster. We will discuss the specifics of how values are transmitted between nodes and within workers when discussing Ray's infrastructure. Although interacting with the object store involves some overhead, it offers improved performance when dealing with larger, more realistic datasets. For now, the crucial aspect is that this step is crucial in a truly distributed environment. If desired, you can try rerunning the previous example with the new retrieve_task function to confirm that it still executes as expected.
Non-blocking calls¶
In a previous example, we used ray.get(object_references) to retrieve results. This call blocks the driver process until all results are available. While this may not be an issue if the program finishes in a short amount of time, it could cause problems if each database item takes several minutes to process. In this case, it would be more efficient to allow the driver process to perform other tasks while waiting for results, and to process results as they are completed rather than waiting for all items to be finished. Additionally, if one of the database items cannot be retrieved due to an issue like a deadlock in the database connection, the driver will hang indefinitely. To prevent this, it is a good idea to set reasonable timeouts using the wait function. For example, if we do not want to wait longer than ten times the longest data retrieval task, we can use the wait function to stop the task after that time has passed.
start = time.time()
object_references = [
retrieve_task.remote(item, db_object_ref) for item in range(8)
]
all_data = []
while len(object_references) > 0:
finished, object_references = ray.wait(
object_references, num_returns=2, timeout=7.0
)
data = ray.get(finished)
print_runtime(data, start)
all_data.extend(data)
print_runtime(all_data, start)
Runtime: 0.11 seconds, data: (0, 'Learning') (1, 'Ray') Runtime: 0.31 seconds, data: (2, 'Flexible') (3, 'Distributed') Runtime: 0.51 seconds, data: (4, 'Python') (5, 'for') Runtime: 0.71 seconds, data: (6, 'Machine') (7, 'Learning') Runtime: 0.71 seconds, data: (0, 'Learning') (1, 'Ray') (2, 'Flexible') (3, 'Distributed') (4, 'Python') (5, 'for') (6, 'Machine') (7, 'Learning')
Instead of simply printing the results, we could have utilized the values that have been retrieved within the while loop to initiate new tasks on other workers.
Task dependencies¶
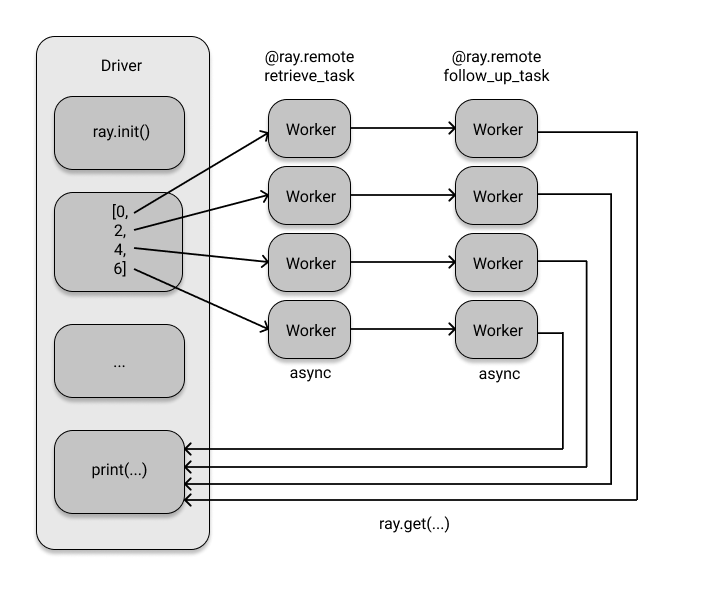
So far, our example program has been straightforward conceptually. It involves one step, which is retrieving a group of items from a database. However, let's say we want to perform an additional processing task on the data after it has been retrieved. For example, we want to use the results from the first retrieval task to query other related data from the same database (for example, from a different table). The code below sets up this follow-up task and executes both the retrieve_task and follow_up_task in sequence.
@ray.remote
def follow_up_task(retrieve_result):
original_item, _ = retrieve_result
follow_up_result = retrieve(original_item + 1)
return retrieve_result, follow_up_result
retrieve_refs = [retrieve_task.remote(item, db_object_ref) for item in [0, 2, 4, 6]]
follow_up_refs = [follow_up_task.remote(ref) for ref in retrieve_refs]
result = [print(data) for data in ray.get(follow_up_refs)]
((0, 'Learning'), (1, 'Ray')) ((2, 'Flexible'), (3, 'Distributed')) ((4, 'Python'), (5, 'for')) ((6, 'Machine'), (7, 'Learning'))
If you're not experienced with asynchronous programming, this example may not seem particularly impressive. However, I hope to demonstrate that it is somewhat surprising that the code even runs. So, what's the significance of this? Essentially, the code appears to be a regular Python function with a few list comprehensions. The point is that the function body of follow_up_task expects a Python tuple for its input argument retrieve_result.
However, when we use the [follow_up_task.remote(ref) for ref in retrieve_refs] command, we are not actually passing tuples to the follow-up task at all. Instead, we are using the retrieve_refs to pass in Ray object references.
Behind the scenes, Ray recognizes that the follow_up_task needs actual values, so it will automatically use the ray.get function to resolve these futures. Additionally, Ray creates a dependency graph for all of the tasks and executes them in a way that respects their dependencies. This means that we don't have to explicitly tell Ray when to wait for a previous task to be completed - it is able to infer this information on its own. This feature of the Ray object store is particularly useful because it allows us to avoid copying large intermediate values back to the driver by simply passing the object references to the next task and letting Ray handle the rest.
The next steps in the process will only be scheduled once the tasks specifically designed to retrieve information are completed. Personally, I believe this is a fantastic feature. In fact, if we had named the retrieve_refs task something like retrieve_result, you might not have even noticed this crucial detail. This was intentional, as Ray wants you to concentrate on your work rather than the technicalities of cluster computing. The dependency graph for the two tasks looks like this:
Ray Actors¶
Before concluding this example, we should cover one more significant aspect of Ray Core. As you can see in our example, everything is essentially a function. We utilized the @ray.remote decorator to make certain functions remote, but besides that, we only used standard Python.
If we want to keep track of how often our database is being queried, we could just count the results of the retrieve tasks. However, is there a more efficient way to do this? Ideally, we want to track this in a distributed manner that can handle a large amount of data. Ray provides a solution with actors, which are used to run stateful computations on a cluster and can also communicate with each other. Similar to how Ray tasks are created using decorated functions, Ray actors are created using decorated Python classes. Therefore, we can create a simple counter using a Ray actor to track the number of database calls.
@ray.remote
class DataTracker:
def __init__(self):
self._counts = 0
def increment(self):
self._counts += 1
def counts(self):
return self._counts
The DataTracker class is an actor because it has been given the ray.remote decorator. This actor is capable of tracking state, such as a counter, and its methods are Ray tasks that can be invoked in the same way as functions using .remote(). We can modify the retrieve_task to incorporate this actor.
@ray.remote
def retrieve_tracker_task(item, tracker, db):
time.sleep(item / 10.)
tracker.increment.remote()
return item, db[item]
tracker = DataTracker.remote()
object_references = [
retrieve_tracker_task.remote(item, tracker, db_object_ref) for item in range(8)
]
data = ray.get(object_references)
print(data)
print(ray.get(tracker.counts.remote()))
[(0, 'Learning'), (1, 'Ray'), (2, 'Flexible'), (3, 'Distributed'), (4, 'Python'), (5, 'for'), (6, 'Machine'), (7, 'Learning')] 8
As expected, the outcome of this calculation is 8. Although we didn't need actors to perform this calculation, it's valuable to have a way to maintain state across the cluster, possibly involving multiple tasks. In fact, we could pass our actor into any related task or even into the constructor of a different actor. The Ray API is very flexible, allowing for limitless possibilities. It's also worth mentioning that it's not common for distributed Python tools to allow for stateful computations like this, making it especially useful for running complex distributed algorithms such as reinforcement learning. This concludes our detailed first example of the Ray API. Let's now try to briefly summarize the Ray API.
Ray Core API Summary¶
Remembering what we did in the previous example, you will see that we only used six API methods. These included ray.init() to initiate the cluster, @ray.remote to transform functions and classes into tasks and actors, ray.put() to transfer values into Ray's object store, and ray.get() to retrieve objects from the cluster. Additionally, we used .remote() on actor methods or tasks to execute code on our cluster, and ray.wait to prevent blocking calls.
Although the Ray API only includes six methods, they are all that you will likely need to use. To make it easier to remember these methods, here's a summary:
- ray.init(): Initializes your Ray cluster. Pass in an address to connect to an existing cluster.
- @ray.remote: Turns functions into tasks and classes into actors.
- ray.put(): Puts values into Ray’s object store.
- ray.get(): Gets valuyes from the object store. Returns the values you’ve put there or that were computed by a task or actor.
- .remote(): Runs actor methods or tasks on your Ray cluster and is used to instantiate actors.
- ray.wait(): Returns two lists of object references, one with finished tasks we’re waiting for and one with unfinished tasks.
Now that you’ve seen the Ray API in action, let’s spend some time on its system architecture.
Ray System Components¶
Now that you are familiar with using the Ray API and understand the design principles behind it, it is time to delve deeper into the inner workings of the Ray system. In other words, how does Ray operate and how does it accomplish its tasks?
Scheduling and Execution¶
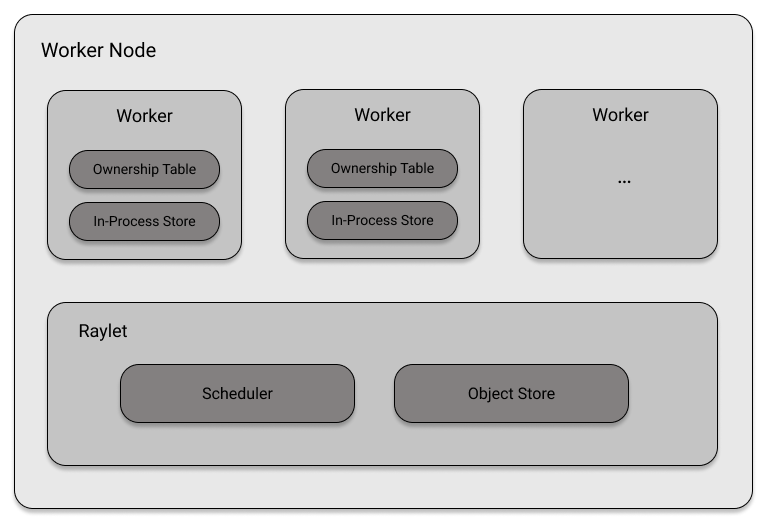
In the Ray cluster system, nodes are made up of individual units called workers. Each worker is identified by a unique ID, IP address, and port. These workers are responsible for carrying out tasks as instructed, but they have no control over when they are given tasks or what resources they have available to complete them. They also have no understanding of the context in which their tasks are being executed, as they do not coordinate with other workers. Before examining the larger cluster as a whole, it is important to understand the role of these individual worker nodes.
To address these issues, each worker node has a component called Raylet. Think of Raylets as the smart components of a node, which manage the worker processes. Raylets are shared between jobs and consist of two components, namely a task scheduler and an object store.
Let's first discuss object stores. In the example provided in this chapter, we have already used the concept of an object store without explicitly stating it. Each node in a Ray cluster is equipped with an object store within its Raylet and all objects stored in these stores form the distributed object store of the cluster. The object store manages the shared memory pool among workers on the same node and ensures that workers can access objects created on other nodes. The object store is implemented using Plasma, which is now part of the Apache Arrow project. Its main function is to manage memory and ensure that workers have access to the objects they need.
The scheduler within a Raylet is responsible for managing resources, including assigning available worker processes to tasks that need access to certain resources such as CPUs. By default, the scheduler is aware of the number of CPUs, GPUs, and amount of memory available on its node. If the scheduler is unable to provide the necessary resources for a task, it must queue the task until resources become available. The scheduler also limits the number of tasks that can run concurrently to prevent overuse of physical resources.
The scheduler is responsible for ensuring that workers have all the necessary resources and dependencies in order to perform their tasks. To do this, the scheduler first checks its own object store for the required values. If these values are not present, the scheduler must reach out to other nodes to retrieve the necessary dependencies. Only once the scheduler has obtained the necessary resources, resolved all dependencies, and identified a worker for the task can it proceed with scheduling the task for execution.
Task scheduling can be challenging, even when only considering a single node. It is easy to envision situations where an improperly or poorly planned task execution can prevent downstream tasks from proceeding due to a lack of available resources. This issue can become even more complex in a distributed setting.
Fault Tolerance and Ownership¶
Now that you have a understanding of Raylets, we will briefly revisit worker processes and conclude the discussion by briefly explaining how Ray is able to recover from failures and the necessary concepts for doing so.
In summary, workers keep track of metadata for all tasks they initiate, as well as the object references returned by those tasks. This is known as ownership, which means that the process that generates an object reference is responsible for ensuring its proper execution and availability of results. Workers must maintain an ownership table to keep track of the tasks they are responsible for, in case any of them fail and need to be redone. This way, if a task fails, the worker already has all the necessary information to recompute it.
To provide a clear illustration of an ownership relationship instead of the idea of dependency that was mentioned before, consider a program that initiates a basic task and then internally calls on another task.
@ray.remote
def task_owned():
return
@ray.remote
def task(dependency):
res_owned = task_owned.remote()
return
val = ray.put("value")
res = task.remote(dependency=val)
To break down the ownership and dependencies in this example, we have two tasks - task and task_owned - and three variables - val, res, and res_owned. The main program owns task, val, and res, and also calls task. However, res depends on task, but there is no ownership relationship between the two. When task is called, it takes val as a dependency and then calls task_owned, which assigns res_owned, therefore owning both task_owned and res_owned. Lastly, task_owned does not own anything, but res_owned depends on it.
The Head Node¶
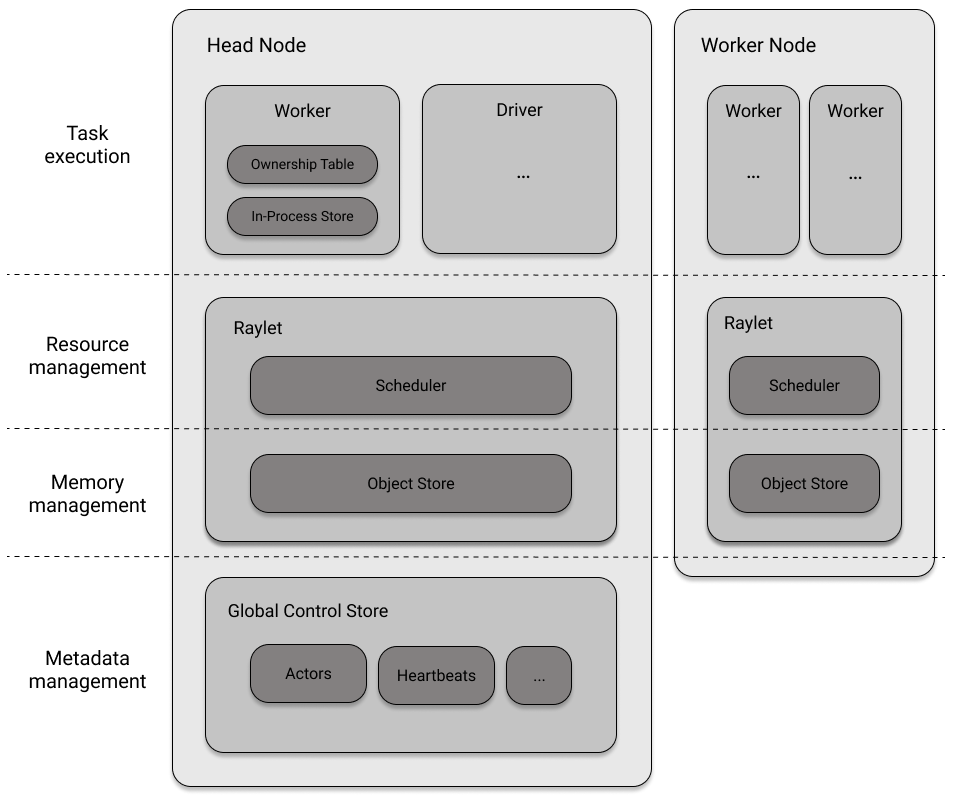
As previously mentioned in Chapter 1, each Ray cluster has a designated head node which has a driver process. While drivers are able to submit tasks, they are unable to execute them. It is also worth noting that the head node can also possess worker processes, which allows for the creation of single node local clusters.
The head node functions in the same way as other worker nodes, but it also runs processes that manage the cluster, such as the autoscaler and the Global Control Service (GCS). The GCS is a key-value store that contains important information about the cluster, including system-level metadata and the locations of Ray actors. It also receives and stores heart beat signals from Raylets to ensure they are still reachable, and sends its own heart beat signals to the Raylets to indicate that it is functioning properly. The ownership model ensures that object information is stored at the worker process responsible for it, preventing the GCS from becoming a bottleneck.
Distributed Scheduling and Execution¶
We will discuss the process of cluster orchestration and how nodes manage, plan, and execute tasks. When discussing worker nodes, we previously mentioned that there are several components involved in distributing workloads using Ray. The following is a summary of the steps and details involved in this process.
- Distributed memory: Each Raylet, which is a unit responsible for managing memory on a particular node, has its own object store. However, there are situations where objects need to be transferred between nodes, a process referred to as distributed object transfer. This occurs in order to address remote dependencies, ensuring that workers have access to the necessary objects to perform their tasks.
- Communication: Most of the communication in a Ray cluster, such as object transfer, takes place via gRPC.
- Resource management and fulfillment: The role of Raylets on a node is to assign resources and assign worker processes to task owners. The distributed scheduler, which consists of schedulers on all nodes, allows tasks to be scheduled on other nodes. Local schedulers are aware of the resources on other nodes through communication with the GCS.
- Task execution: Before a task can be executed, all of its dependencies, including both local and remote data, must be resolved. For example, this might involve retrieving large data from the object store.
Now that you’ve learned the basics of the Ray Core API and know the fundamentals of Ray’s Cluster architecture, let’s compute one more complex example
Running A MapReduce Example¶
It would be remiss to conclude this conversation without mentioning MapReduce, a significant development in distributed computing in recent decades. Many popular big data technologies, such as Hadoop, are built upon this programming model, and it is worth discussing in relation to Ray. To illustrate its use, we will use a simple example of counting word occurrences across multiple documents. While this may seem like a straightforward task when working with a small number of documents, it becomes more complex when dealing with a large corpus, requiring the use of multiple compute nodes to process the data.
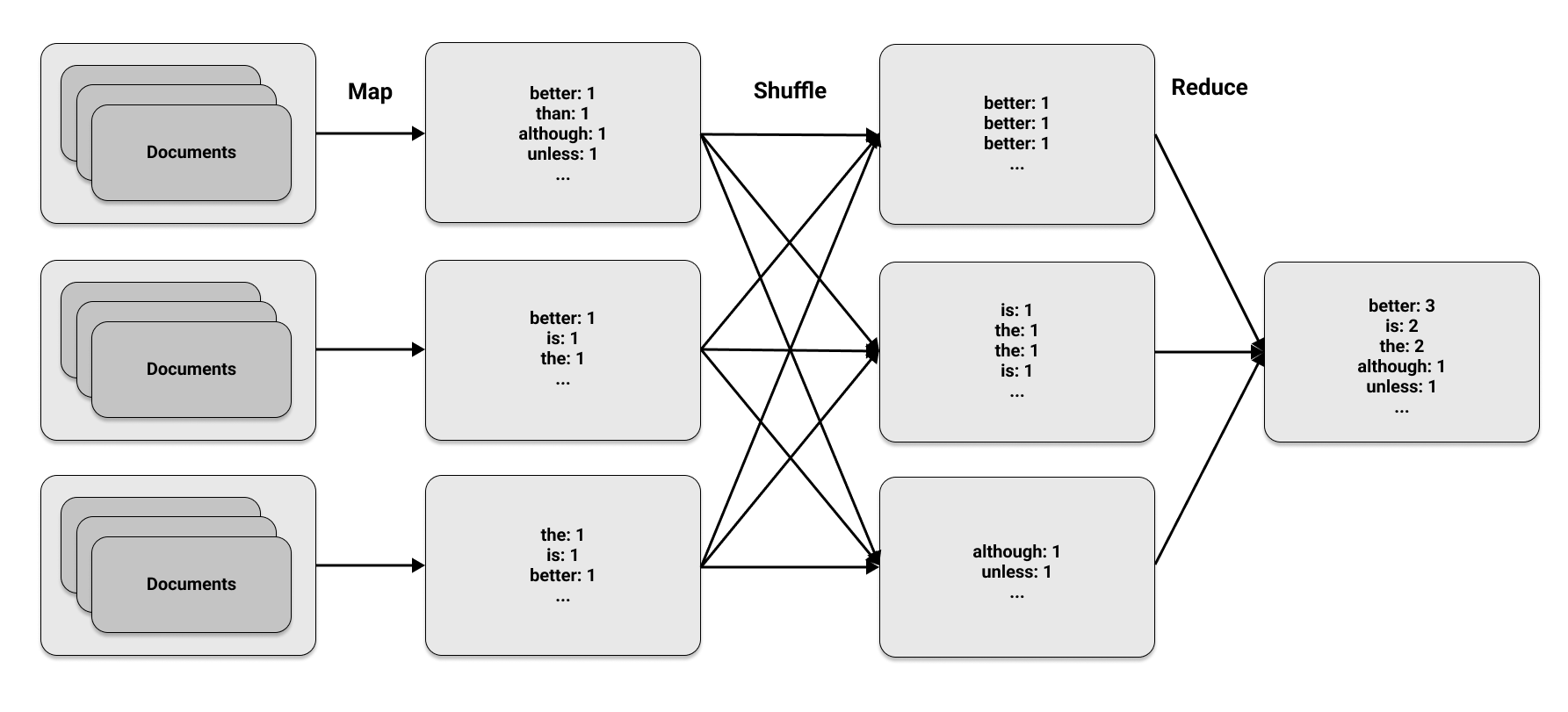
A MapReduce word-count example is a commonly used example in distributed computing and is worth learning about. The approach involves three simple steps:
- Use a set of documents as the input and apply a specified function to transform or "map" each element within them (such as the words contained in the documents). This map phase will produce key-value pairs, where the key represents an element in the document and the value is a metric calculated for that element. In this particular case, the goal is to count the number of times each word appears in a document, so the map function will output the pair
(word, 1)every time a word is encountered to show that it has been found once. - All of the outputs from the map phase are collected and organized based on their key. This may involve transferring data between different nodes, as the same key could potentially be found on multiple compute nodes. This process is commonly referred to as the shuffle phase. As an example, if the map phase produces four occurrences of the pair
(word, 1), the shuffle phase will ensure that all occurrences of the same word are located on the same node. - The reduce phase is so named because it aggregates or combines the elements from the shuffle step. Using the example provided, the final count of a word's occurrences is obtained by adding up all of the occurrences on each node. For example, four instances of
(word, 1)would be combined to result in a final count ofword: 4.
MapReduce is named after the first and last stages of the process, but the middle stage is just as crucial. These phases may appear straightforward, but their strength lies in the ability to run them concurrently on multiple machines. An example of using the three MapReduce phases on a set of documents divided into three parts is shown in this figure:
We will be using Python to implement the MapReduce algorithm for our word-count purpose and utilizing Ray to parallelize the computation. To better understand what we are working with, we will begin by loading some example data.
import subprocess
zen_of_python = subprocess.check_output(["python", "-c", "import this"])
corpus = zen_of_python.split()
num_partitions = 3
chunk = len(corpus) // num_partitions
partitions = [
corpus[i * chunk: (i + 1) * chunk] for i in range(num_partitions)
]
We will be using the Zen of Python, a collection of guidelines from the Python community, as our data for this exercise. The Zen of Python can be accessed by typing "import this" in a Python session and is traditionally hidden as an "Easter egg." While it is beneficial for Python programmers to read these guidelines, for the purposes of this exercise, we will only be counting the number of words contained within them. To do this, we will divide the Zen of Python into three separate "documents" by treating each line as a separate entity and then splitting it into these partitions.
To determine the map phase, we require a map function that we will utilize on each document. In this particular scenario, we want to output the pair (word, 1) for every word found in a document. For basic text documents that are loaded as Python strings, this process appears as follows.
def map_function(document):
for word in document.lower().split():
yield word, 1
We will use the apply_map function on a large collection of documents by marking it as a task in Ray using the @ray.remote decorator. When we call apply_map, it will be applied to three sets of document data (num_partitions=3). The apply_map function will return three lists, one for each partition. We do this so that Ray can rearrange the results of the map phase and distribute them to the appropriate nodes for us.
import ray
@ray.remote
def apply_map(corpus, num_partitions=3):
map_results = [list() for _ in range(num_partitions)]
for document in corpus:
for result in map_function(document):
first_letter = result[0].decode("utf-8")[0]
word_index = ord(first_letter) % num_partitions
map_results[word_index].append(result)
return map_results
For text corpora that can be stored on a single machine, it is unnecessary to use the map phase. However, when the data needs to be divided across multiple nodes, the map phase becomes useful. In order to apply the map phase to our corpus in parallel, we use a remote call on apply_map, just like we have done in previous examples. The main difference now is that we also specify that we want three results returned (one for each partition) using the num_returns argument.
map_results = [
apply_map.options(num_returns=num_partitions)
.remote(data, num_partitions)
for data in partitions
]
for i in range(num_partitions):
mapper_results = ray.get(map_results[i])
for j, result in enumerate(mapper_results):
print(f"Mapper {i}, return value {j}: {result[:2]}")
Mapper 0, return value 0: [(b'of', 1), (b'is', 1)] Mapper 0, return value 1: [(b'python,', 1), (b'peters', 1)] Mapper 0, return value 2: [(b'the', 1), (b'zen', 1)] Mapper 1, return value 0: [(b'unless', 1), (b'in', 1)] Mapper 1, return value 1: [(b'although', 1), (b'practicality', 1)] Mapper 1, return value 2: [(b'beats', 1), (b'errors', 1)] Mapper 2, return value 0: [(b'is', 1), (b'is', 1)] Mapper 2, return value 1: [(b'although', 1), (b'a', 1)] Mapper 2, return value 2: [(b'better', 1), (b'than', 1)]
We can make it so that all pairs from the j-th return value end up on
the same node for the reduce phase. Let’s discuss this phase next.
In the reduce phase we can create a dictionary that sums up all word occurrences on each partition:
@ray.remote
def apply_reduce(*results):
reduce_results = dict()
for res in results:
for key, value in res:
if key not in reduce_results:
reduce_results[key] = 0
reduce_results[key] += value
return reduce_results
We can take the j-th return value from each mapper and send it to the j-th reducer using the following method. It's important to note that this code works for larger datasets that don't fit on one machine because we are passing references to the data using Ray objects rather than the actual data itself. Both the map and reduce phases can be run on any Ray cluster and the data shuffling is also handled by Ray.
outputs = []
for i in range(num_partitions):
outputs.append(
apply_reduce.remote(*[partition[i] for partition in map_results])
)
counts = {k: v for output in ray.get(outputs) for k, v in output.items()}
sorted_counts = sorted(counts.items(), key=lambda item: item[1], reverse=True)
for count in sorted_counts:
print(f"{count[0].decode('utf-8')}: {count[1]}")
is: 10 better: 8 than: 8 the: 6 to: 5 of: 3 although: 3 be: 3 unless: 2 one: 2 if: 2 implementation: 2 idea.: 2 special: 2 should: 2 do: 2 may: 2 a: 2 never: 2 way: 2 explain,: 2 ugly.: 1 implicit.: 1 complex.: 1 complex: 1 complicated.: 1 flat: 1 readability: 1 counts.: 1 cases: 1 rules.: 1 in: 1 face: 1 refuse: 1 one--: 1 only: 1 --obvious: 1 it.: 1 obvious: 1 first: 1 often: 1 *right*: 1 it's: 1 it: 1 idea: 1 --: 1 let's: 1 python,: 1 peters: 1 simple: 1 sparse: 1 dense.: 1 aren't: 1 practicality: 1 purity.: 1 pass: 1 silently.: 1 silenced.: 1 ambiguity,: 1 guess.: 1 and: 1 preferably: 1 at: 1 you're: 1 dutch.: 1 good: 1 are: 1 great: 1 more: 1 zen: 1 by: 1 tim: 1 beautiful: 1 explicit: 1 nested.: 1 enough: 1 break: 1 beats: 1 errors: 1 explicitly: 1 temptation: 1 there: 1 that: 1 not: 1 now: 1 never.: 1 now.: 1 hard: 1 bad: 1 easy: 1 namespaces: 1 honking: 1 those!: 1
To gain a thorough understanding of how to scale MapReduce tasks across multiple nodes using Ray, including memory management, we suggest reading this insightful blog post on the topic.
The important part about this MapReduce example is to realize how flexible Ray’s programming model really is. Surely, a production-grade MapReduce implementation takes a bit more effort. But being able to reproduce common algorithms like this one quickly goes a long way. Keep in mind that in the earlier phases of MapReduce, say around 2010, this paradigm was often the only thing you had to express your workloads. With Ray, a whole range of interesting distributed computing patterns become accessible to any intermediate Python programmer.