An Overview of Ray¶
One of the reasons we need efficient distributed computing is that we’re collecting ever more data with a large variety at increasing speeds. The storage systems, data processing and analytics engines that have emerged in the last decade are crucially important to the success of many companies. Interestingly, most “big data” technologies are built for and operated by (data) engineers, that are in charge of data collection and processing tasks. The rationale is to free up data scientists to do what they’re best at. As a data science practitioner you might want to focus on training complex machine learning models, running efficient hyperparameter selection, building entirely new and custom models or simulations, or serving your models to showcase them.
At the same time, it might be inevitable to scale these workloads to a compute cluster. To do that, the distributed system of your choice needs to support all of these fine-grained “big compute” tasks, potentially on specialized hardware. Ideally, it also fits into the big data tool chain you’re using and is fast enough to meet your latency requirements. In other words, distributed computing has to be powerful and flexible enough for complex data science workloads — and Ray can help you with that.
Python is likely the most popular language for data science today, and it’s certainly the one we find the most useful for our daily work. By now it’s over 30 years old, but has a still growing and active community. The rich PyData ecosystem is an essential part of a data scientist’s toolbox. How can you make sure to scale out your workloads while still leveraging the tools you need? That’s a difficult problem, especially since communities can’t be forced to just toss their toolbox, or programming language. That means distributed computing tools for data science have to be built for their existing community
Every chapter of this book has an executable notebook that you can run. If you want run the code while following this chapter, you can run this notebook locally or directly in Colab:
![]()
For this chapter you need to install the following dependencies. We guide you through each dependency and when you need it later on, but if you're impatient you can install them all right now:
! pip install "ray[rllib, serve, tune]==2.2.0"
! pip install "pyarrow==10.0.0"
! pip install "tensorflow>=2.9.0"
! pip install "transformers>=4.24.0"
! pip install "pygame==2.1.2" "gym==0.25.0"
To import utility files for this chapter on Colab you will also have to clone the repo and copy the code files to the base path of the runtime. You don't need to do this if you run the notebook locally, of course.
!git clone https://github.com/maxpumperla/learning_ray
%cp -r learning_ray/notebooks/* .
What is Ray?¶
Ray is a great computing framework for the Python data science community because it is flexible and distributed, making it easy to use and understand. It allows you to efficiently parallelize Python programs on your own computer and run them on a cluster without much modification. Additionally, its high-level libraries are easy to set up and can be used together smoothly, and some of them, such as the reinforcement learning library, have a promising future as standalone projects. Even though its core is written in C++, Ray has always been focused on Python and integrates well with many important data science tools. It also has a expanding ecosystem.
Ray is not the first framework for distributed Python, nor will it be the last, but it stands out for its ability to handle custom machine learning tasks with ease. Its various modules work well together, allowing for the flexible execution of complex workloads using familiar Python tools. This book aims to teach how to use Ray to effectively utilize distributed Python for machine learning purposes.
Programming distributed systems can be challenging because it requires specific skills and experience. While these systems are designed to be efficient and allow users to focus on their tasks, they often have "leaky abstractions" that can make it difficult to get clusters of computers to work as desired. In addition, many software systems require more resources than a single server can provide, and modern systems need to be able to handle failures and offer high availability. This means that applications may need to run on multiple machines or even in different data centers in order to function reliably.
Even if you are not very familiar with machine learning (ML) or artificial intelligence (AI), you have probably heard about recent advances in these fields. Some examples of these advances include Deepmind's Alpha-Fold, which is a system for solving the protein folding problem, and OpenAI's Codex, which helps software developers with the tedious parts of their job. It is commonly known that ML systems require a lot of data to be trained and that ML models tend to become larger. OpenAI has demonstrated that the amount of computing power needed to train AI models has been increasing exponentially, as shown in their paper "AI and Compute." In their study, the operations needed for AI systems were measured in petaflops (thousands of trillion operations per second) and have doubled every 3.4 months since 2012.
While Moore's Law suggests that computer transistors will double every two years, the use of distributed computing in machine learning can significantly increase the speed at which tasks are completed. While distributed computing may be seen as challenging, it would be beneficial to develop abstractions that allow for code to run on clusters without constantly considering individual machines and their interactions. By focusing specifically on AI workloads, it may be possible to make distributed computing more accessible and efficient.
Researchers at RISELab at UC Berkeley developed Ray to improve the efficiency of their workloads by distributing them. These workloads were flexible in nature and did not fit into existing frameworks. Ray was also designed to handle the distribution of the work and allow researchers to focus on their work without worrying about the specifics of their compute cluster. It was created with a focus on high-performance and diverse workloads, and allows researchers to use their preferred Python tools.
Design Philosophy¶
Ray was created with a focus on certain design principles. Its API aims to be straightforward and applicable to a wide range of situations, while the compute model is designed to be adaptable. Additionally, the system architecture is optimized for speed and the ability to handle increasing workloads. Let's delve into these points further.
Simplicity and abstraction¶
Ray's API is not only simple to use, but it is also intuitive and easy to learn, as you will see in Chapter 2. Whether you want to use all the CPU cores on your laptop or leverage all the machines in your cluster, you can do so with minimal changes to your code. Ray handles task distribution and coordination behind the scenes, allowing you to focus on your work rather than worrying about the mechanics of distributed computing. Additionally, the API is very flexible and can easily be integrated with other tools. For example, Ray actors can interact with other distributed Python workloads, making it a useful "glue code" for connecting different systems and frameworks.
Flexibility and heterogeneity¶
Ray's API is created to allow users to easily write flexible and modular code for artificial intelligence tasks, especially those involving reinforcement learning. As long as the workload can be expressed in Python, it can be distributed using Ray. However, it is important to ensure that sufficient resources are available and to consider what should be distributed. Ray does not impose any limitations on what can be done with it.
Ray is able to handle a variety of different computational tasks. For example, when working on a complex simulation, it is common for there to be different steps that take different amounts of time to complete. Some may take a long time while others only take a few milliseconds. Ray is able to efficiently schedule and execute these tasks, even if they need to be run in parallel. Additionally, Ray's framework allows for dynamic execution, which is helpful when subsequent tasks depend on the outcome of an earlier task. Overall, Ray provides flexibility in managing heterogeneous workflows.
It is important to be able to adapt your resource usage and Ray allows for the use of different types of hardware. For example, certain tasks may require the use of a GPU while others may perform better on a CPU. Ray gives you the ability to choose the most appropriate hardware for each task.
Speed and scalability¶
One of the key features of Ray is its speed. It can handle millions of tasks per second with minimal latency, making it an efficient choice for distributed systems. Additionally, Ray is effective at distributing and scheduling tasks across a compute cluster, and it does so in a way that is fault-tolerant. Its auto-scaler can adjust the number of machines in the cluster to match current demand, which helps to minimize costs and ensure there are enough resources available to run workloads. In the event of failures, Ray is designed to recover quickly, further contributing to its overall speed. While we will delve into the specifics of Ray's architecture later on, for now, let's focus on how it can be used in practice.
Core, Libraries and Ecosystem¶
Now that you are aware of the purpose and goals behind the creation of Ray, let's examine the three layers of the system. While there may be other ways to classify these layers, the approach used in this book is the most logical and understandable.
- A low-level, distributed computing framework for Python with a concise core API and tooling for cluster deployment called Ray Core.
- A set of high-level libraries for built and maintained by the creators of Ray. This includes the so-called Ray AI Runtime (AIR) to use these libraries with a unified API in common machine learning workloads.
- A growing ecosystem of integrations and partnerships with other notable projects, which span many aspects of the first two layers.
There are several layers to explore in this chapter. The core of Ray's engine, with its API at the center, serves as the foundation for everything else. The data science libraries in Ray build on top of this core and offer a specialized interface. Many data scientists will use these libraries directly, while those working in ML or platform engineering may focus on creating tools that extend the Ray Core API. Ray AIR serves as a connector between the various Ray libraries and provides a consistent framework for handling common AI tasks. Additionally, there are a increasing number of third-party integrations available for Ray that can be utilized by experienced practitioners. We will examine each of these layers in more detail.
Below is a quick preview of what libraries and integrations each layer consists of. Maybe you already spot a few of your favorite tools from the ecosystem.
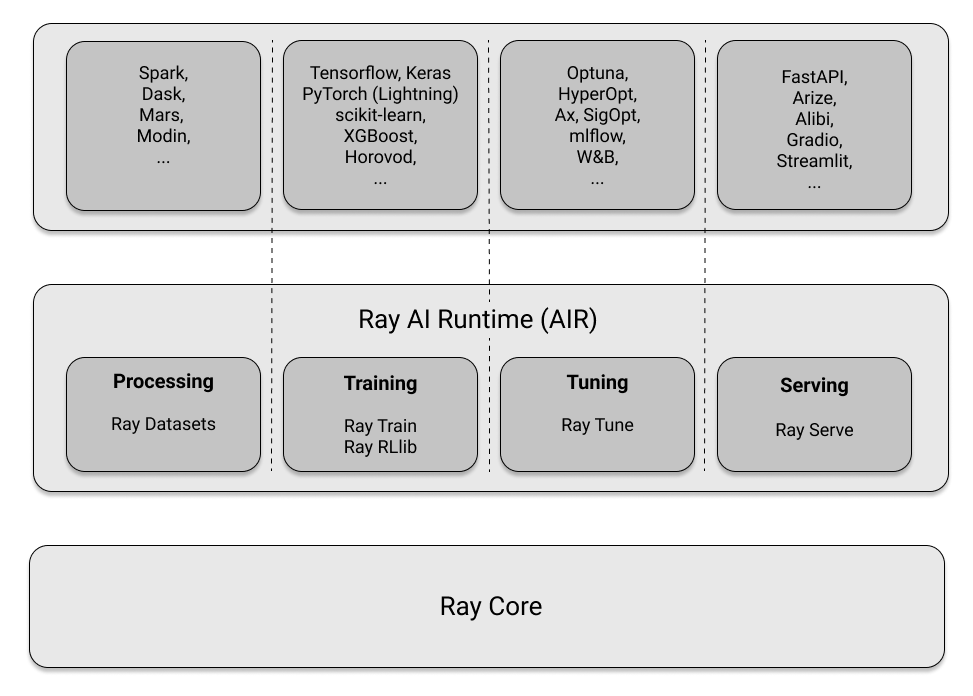
A framework for distributed computing¶
At its core, Ray is a distributed computing framework. We'll provide you with just the basic terminology here, and talk about Ray's architecture in depth in chapter 2. In short, Ray sets up and manages clusters of computers so that you can run distributed tasks on them. A ray cluster consists of nodes that are connected to each other via a network. You program against the so-called driver, the program root, which lives on the head node. The driver can run jobs, that is a collection of tasks, that are run on the nodes in the cluster. Specifically, the individual tasks of a job are run on worker processes on worker nodes_.
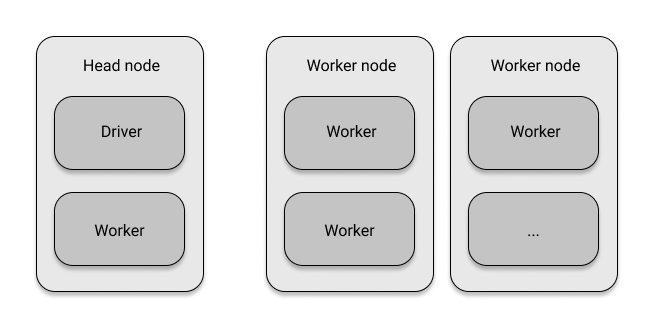
What's interesting is that a Ray cluster can also be a local cluster, i.e. a cluster consisting just of your own computer. In this case, there's just one node, namely the head node, which has the driver process and some worker processes.
With that knowledge at hand, it's time to get your hands dirty and run your first
local Ray cluster.
Installing Ray on any of the major operating systems should work seamlessly
using pip:
pip install "ray[rllib, tune, serve]==2.2.0"With a simple pip install ray you would have installed just the very basics of Ray.
Since we want to explore some advanced features, we installed the "extras" rllib
and tune, which we'll discuss in a bit.
Depending on your system configuration you may not need the quotation marks in the
above installation command.
Next, go ahead and start a Python session.
You could use the ipython interpreter, which I find to be the most suitable
environment for following along simple examples.
The choice is up to you, but in any case please remember to use Python version
3.7 or later.
In your Python session you can now easily import and initialize Ray as follows:
import ray
ray.init()
2022-12-20 10:05:02,372 INFO worker.py:1529 -- Started a local Ray instance. View the dashboard at 127.0.0.1:8265
Ray
| Python version: | 3.9.13 |
| Ray version: | 2.2.0 |
| Dashboard: | http://127.0.0.1:8265 |
By running those two lines of code, you have set up a Ray cluster on your local machine. This cluster can take advantage of all the cores on your computer as worker processes. Currently, your Ray cluster isn't doing much, but that will change in the following section. The init function used to initiate the cluster is one of just six fundamental API calls that you will delve into in Chapter 2. Overall, the Ray Core API is straightforward and easy to use, but since it is also a lower-level interface, it takes time to create more complex examples with it. Chapter 2 includes a detailed first example to introduce you to the Ray Core API, and in Chapter 3 you will see how to build a more advanced Ray application for reinforcement learning.
In the above example, you did not provide any arguments when calling the ray.init(...) function. If you wanted to use Ray on a real cluster, you would need to include more arguments in this init call, which is known as the Ray Client. The Ray Client is used to connect to an existing Ray cluster and interact with it. If you are interested in learning more about using the Ray Client to connect to your production clusters, you can refer to the Ray documentation. Keep in mind that working with compute clusters can be complex, and there are many options for deploying Ray applications on them. For example, you can use cloud providers like AWS, GCP, or Azure to host your Ray clusters, or you can set up your own hardware or use tools like Kubernetes. We will revisit the topic of scaling workloads with Ray Clusters in Chapter 9, after discussing some specific applications of Ray in earlier chapters.
Before moving on the Ray’s higher level libraries, let’s briefly summarize the two foundational components of Ray as a distributed computation framework:
- Ray Clusters: This component is in charge of allocating resources, creating nodes, and ensuring they are healthy. A good way to get started with Ray Clusters is its dedicated quick start guide (https://docs.ray.io/en/latest/cluster/quickstart.html).
- Ray Core: Once your cluster is up and running, you use the Ray Core API that to program against it. You can get started with Ray Core by following the official walk-through (https://docs.ray.io/en/latest/ray-core/walkthrough.html) for this component.
Ray's Libraries¶
In this section, we will introduce the data science libraries included with Ray. To understand how these libraries can be beneficial to you, it's important to first have a general understanding of what data science entails. With this context in mind, you'll be able to see how Ray's higher-level libraries fit into the larger picture.
Ray AIR and the Data Science Workflow¶
The concept of "data science" (DS) has undergone significant changes in recent years, and you can find various definitions of the term online, some more useful than others. However, we believe that data science is the practice of using data to gain insights and develop practical applications. It is a field that involves building and understanding things, and is therefore quite practical and applied. In this sense, calling practitioners of this field "data scientists" is similar to calling hackers "computer scientists".
Data science involves a series of steps that involve identifying and gathering the necessary data, processing it, creating models, and implementing solutions. While machine learning may be a part of this process, it is not always necessary. If machine learning is included, there may be additional steps involved.
- Data Processing: To use machine learning effectively, you must prepare the data in a way that the ML model can understand. This process, called feature engineering, involves selecting and transforming the data that will be input into the model. It can be a challenging task, so it is helpful to have access to reliable tools to assist with it.
- Model Training: For machine learning, it is necessary to train your algorithms on data that has been previously processed. This involves selecting the appropriate algorithm for the task at hand. Having a diverse range of algorithms to choose from can also be beneficial.
- Hyperparameter Tuning: During the process of training a machine learning model, certain parameters can be fine-tuned in order to improve its performance. In addition to these model parameters, there are also hyperparameters that can be adjusted before training begins. The proper adjustment of these hyperparameters can significantly impact the effectiveness of the final machine learning model. Fortunately, there are tools available to assist with the process of optimizing these hyperparameters.
- Model Serving: The deployment of trained models is necessary in order to provide access to them for those who need it. This process, known as serving a model, involves making it available through various means, such as using simple HTTP servers in prototypes or specialized software packages specifically designed for serving ML models.
It is important to note that this list is not exhaustive and there is more to consider when building machine learning applications. Nonetheless, it is undeniable that these four steps are critical for the success of a data science project that utilizes machine learning.
Ray has created dedicated libraries for each of the four ML-specific steps mentioned earlier. These libraries include Ray Datasets for data processing, Ray Train for distributed model training, Ray RLlib for reinforcement learning workloads, Ray Tune for efficient hyperparameter tuning, and Ray Serve for serving models. It is important to note that all of these libraries are distributed by design, as that is how Ray is built.
Additionally, it is important to consider that these steps are usually not completed separately but rather as part of a larger process. It is beneficial to have all relevant libraries working smoothly together and to have a uniform API throughout the data science process. The Ray AI Runtime (AIR) was designed with this in mind, providing a common runtime and API for experiments and the capability to expand workloads as needed.
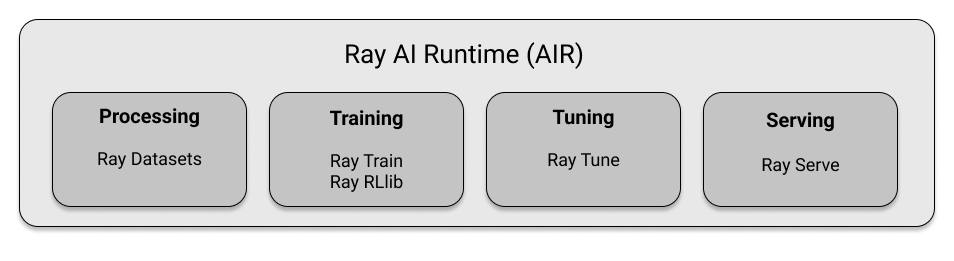
In this chapter, we will not be discussing the Ray AI Runtime API in depth (more on that can be found in Chapter 10). However, we can provide an overview of the components that contribute to it. Specifically, we will go through each of the DS libraries that make up Ray one by one.
Ray Data¶
The first high-level library of Ray we talk about is called "Ray Data".
This library contains a data structure aptly called Dataset, a multitude of
connectors for loading data from various formats and systems,
an API for transforming such datasets, a way to build data processing pipelines
with them, and many integrations with other data processing frameworks.
The Dataset abstraction builds on the powerful
Arrow framework.
To use Ray Data, you need to install Arrow for Python, for instance by running
pip install pyarrow.
We'll now discuss a simple example that creates a distributed Dataset on your
local Ray cluster from a Python data structure.
Specifically, you'll create a dataset from a Python dictionary containing a
string name and an integer-valued data for 10000 entries:
import ray
items = [{"name": str(i), "data": i} for i in range(10000)]
ds = ray.data.from_items(items)
ds.show(5)
{'name': '0', 'data': 0}
{'name': '1', 'data': 1}
{'name': '2', 'data': 2}
{'name': '3', 'data': 3}
{'name': '4', 'data': 4}
Great, now you have some rows, but what can you do with that data?
The Dataset API bets heavily on functional programming, as it is very well suited
for data transformations.
Even though Python 3 made a point of hiding some of its functional programming
capabilities, you're probably
familiar with functionality such as map, filter and others.
If not, it's easy enough to pick up.
map takes each element of your dataset and transforms is into something
else, in parallel.
filter removes data points according to a boolean filter function.
And the slightly more elaborate flat_map first maps values similarly to map,
but then also "flattens" the result.
For instance, if map would produce a list of lists, flat_map would flatten out
the nested lists and give
you just a list.
Equipped with these three functional API calls, let's see how easily you can
transform your dataset ds:
squares = ds.map(lambda x: x["data"] ** 2)
evens = squares.filter(lambda x: x % 2 == 0)
evens.count()
cubes = evens.flat_map(lambda x: [x, x**3])
sample = cubes.take(10)
print(sample)
2022-12-20 10:05:43,431 WARNING dataset.py:4233 -- The `map`, `flat_map`, and `filter` operations are unvectorized and can be very slow. Consider using `.map_batches()` instead. Map: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 200/200 [00:01<00:00, 139.83it/s] Filter: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 200/200 [00:00<00:00, 1144.95it/s] Flat_Map: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 200/200 [00:00<00:00, 1193.90it/s]
[0, 0, 4, 64, 16, 4096, 36, 46656, 64, 262144]
The drawback of Dataset transformations is that each step gets executed
synchronously.
In the above example this is a non-issue, but for complex tasks that e.g. mix
reading files and processing data,
you want an execution that can overlap the individual tasks.
DatasetPipeline does exactly that.
Let's rewrite the last example into a pipeline.
pipe = ds.window()
result = pipe\
.map(lambda x: x["data"] ** 2)\
.filter(lambda x: x % 2 == 0)\
.flat_map(lambda x: [x, x**3])
result.show(10)
2022-12-20 10:05:49,790 INFO dataset.py:3693 -- Created DatasetPipeline with 20 windows: 7390b min, 8000b max, 7944b mean 2022-12-20 10:05:49,791 INFO dataset.py:3703 -- Blocks per window: 10 min, 10 max, 10 mean 2022-12-20 10:05:49,793 WARNING dataset.py:3715 -- ⚠️ This pipeline's parallelism is limited by its blocks per window to ~10 concurrent tasks per window. To maximize performance, increase the blocks per window to at least 12. This may require increasing the base dataset's parallelism and/or adjusting the windowing parameters. 2022-12-20 10:05:49,794 INFO dataset.py:3742 -- ✔️ This pipeline's windows likely fit in object store memory without spilling. Stage 0: 0%| | 0/20 [00:00<?, ?it/s] 0%| | 0/20 [00:00<?, ?it/s] Stage 1: 5%|█████████▎ | 1/20 [00:00<00:01, 9.56it/s] Stage 0: 10%|██████████████████▋ | 2/20 [00:00<00:00, 18.57it/s]
0 0 4 64 16 4096 36 46656 64 262144
While there is much more that can be explored regarding Ray Datasets and its integration with certain data processing systems, we will have to postpone a more thorough discussion until Chapter 6.
Model Training¶
Next, we will examine the distributed training abilities of Ray through two libraries. The first library is specifically for reinforcement learning, while the second library is primarily focused on supervised learning tasks.
RL with Ray RLlib¶
We will begin with discussing Ray RLlib for reinforcement learning, a library that utilizes either TensorFlow or PyTorch as its underlying machine learning framework. Both of these frameworks are highly compatible with each other, so you can use whichever one you prefer without sacrificing much in terms of functionality. In this book, we will provide examples using both TensorFlow and PyTorch to give you a comprehensive understanding of how to use Ray with either framework. In this chapter we'll work with TensorFlow, which you can install by simply running the command "pip install tensorflow" in your terminal. If you wanted to, you could equally well install PyTorch instead.
RLlib provides a command line tool called rllib that can be easily used to run examples. It was already installed when you ran "pip install 'ray[rllib]'" earlier. While you will primarily use the Python API for more advanced examples in Chapter 4, this tool allows you to quickly try out RL experiments using RLlib.
We will consider a classic control problem in which we try to balance a pole on a cart. Imagine that the pole is attached to the cart at a joint and is subject to the force of gravity. The cart is able to move along a frictionless track and we can give it a push to the left or right with a fixed force. If we do this properly, the pole should remain upright. For each time step in which the pole does not fall, we receive a reward of 1. Our goal is to collect as many rewards as possible and we want to see if we can use a reinforcement learning algorithm to help us achieve this.
Our goal is to train a reinforcement learning agent that can perform two actions: pushing to the left or to the right, observe the consequences of these actions, and learn from the experience to maximize the reward. To achieve this using Ray RLlib, we can utilize a "tuned example," which is a pre-set algorithm that works effectively for a specific problem. These examples can be easily run with a single command and RLlib offers a variety of them, which can be viewed by using this command:
! rllib example list
RLlib Examples ┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Example ID ┃ Description ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ atari-a2c │ Runs grid search over several Atari games │ │ │ on A2C. │ │ atari-dqn │ Run grid search on Atari environments with │ │ │ DQN. │ │ atari-duel-ddqn │ Run grid search on Atari environments with │ │ │ duelling double DQN. │ │ atari-impala │ Run grid search over several atari games │ │ │ with IMPALA. │ │ atari-ppo │ Run grid search over several atari games │ │ │ with PPO. │ │ atari-sac │ Run grid search on several atari games │ │ │ with SAC. │ │ breakout-apex-dqn │ Runs Apex DQN on BreakoutNoFrameskip-v4. │ │ breakout-ddppo │ Runs DDPPO on BreakoutNoFrameskip-v4. │ │ cartpole-a2c │ Runs A2C on the CartPole-v1 environment. │ │ cartpole-a2c-micro │ Runs A2C on the CartPole-v1 environment, │ │ │ using micro-batches. │ │ cartpole-a3c │ Runs A3C on the CartPole-v1 environment. │ │ cartpole-alpha-zero │ Runs AlphaZero on a Cartpole with sparse │ │ │ rewards. │ │ cartpole-apex-dqn │ Runs Apex DQN on CartPole-v1. │ │ cartpole-appo │ Runs APPO on CartPole-v1. │ │ cartpole-ars │ Runs ARS on CartPole-v1. │ │ cartpole-bc │ Runs BC on CartPole-v1. │ │ cartpole-crr │ Run CRR on CartPole-v1. │ │ cartpole-ddppo │ Runs DDPPO on CartPole-v1 │ │ cartpole-dqn │ Run DQN on CartPole-v1. │ │ cartpole-dt │ Run DT on CartPole-v1. │ │ cartpole-es │ Run ES on CartPole-v1. │ │ cartpole-impala │ Run IMPALA on CartPole-v1. │ │ cartpole-maml │ Run MAML on CartPole-v1. │ │ cartpole-marwil │ Run MARWIL on CartPole-v1. │ │ cartpole-mbmpo │ Run MBMPO on a CartPole environment │ │ │ wrapper. │ │ cartpole-pg │ Run PG on CartPole-v1 │ │ cartpole-ppo │ Run PPO on CartPole-v1. │ │ cartpole-sac │ Run SAC on CartPole-v1 │ │ cartpole-simpleq │ Run SimpleQ on CartPole-v1 │ │ dm-control-dreamer │ Run DREAMER on a suite of control problems │ │ │ by Deepmind. │ │ frozenlake-appo │ Runs APPO on FrozenLake-v1. │ │ halfcheetah-appo │ Runs APPO on HalfCheetah-v2. │ │ halfcheetah-bullet-ddpg │ Runs DDPG on HalfCheetahBulletEnv-v0. │ │ halfcheetah-cql │ Runs grid search on HalfCheetah │ │ │ environments with CQL. │ │ halfcheetah-ddpg │ Runs DDPG on HalfCheetah-v2. │ │ halfcheetah-maml │ Run MAML on a custom HalfCheetah │ │ │ environment. │ │ halfcheetah-mbmpo │ Run MBMPO on a HalfCheetah environment │ │ │ wrapper. │ │ halfcheetah-ppo │ Run PPO on HalfCheetah-v2. │ │ halfcheetah-sac │ Run SAC on HalfCheetah-v3. │ │ hopper-bullet-ddpg │ Runs DDPG on HopperBulletEnv-v0. │ │ hopper-cql │ Runs grid search on Hopper environments │ │ │ with CQL. │ │ hopper-mbmpo │ Run MBMPO on a Hopper environment wrapper. │ │ hopper-ppo │ Run PPO on Hopper-v1. │ │ humanoid-es │ Run ES on Humanoid-v2. │ │ humanoid-ppo │ Run PPO on Humanoid-v1. │ │ inverted-pendulum-td3 │ Run TD3 on InvertedPendulum-v2. │ │ mountaincar-apex-ddpg │ Runs Apex DDPG on │ │ │ MountainCarContinuous-v0. │ │ mountaincar-ddpg │ Runs DDPG on MountainCarContinuous-v0. │ │ mujoco-td3 │ Run TD3 against four of the hardest MuJoCo │ │ │ tasks. │ │ multi-agent-cartpole-alpha-star │ Runs AlphaStar on 4 CartPole agents. │ │ multi-agent-cartpole-appo │ Runs APPO on RLlib's MultiAgentCartPole │ │ multi-agent-cartpole-impala │ Run IMPALA on RLlib's MultiAgentCartPole │ │ pacman-sac │ Run SAC on MsPacmanNoFrameskip-v4. │ │ pendulum-apex-ddpg │ Runs Apex DDPG on Pendulum-v1. │ │ pendulum-appo │ Runs APPO on Pendulum-v1. │ │ pendulum-cql │ Runs CQL on Pendulum-v1. │ │ pendulum-crr │ Run CRR on Pendulum-v1. │ │ pendulum-ddpg │ Runs DDPG on Pendulum-v1. │ │ pendulum-ddppo │ Runs DDPPO on Pendulum-v1. │ │ pendulum-dt │ Run DT on Pendulum-v1. │ │ pendulum-impala │ Run IMPALA on Pendulum-v1. │ │ pendulum-maml │ Run MAML on a custom Pendulum environment. │ │ pendulum-mbmpo │ Run MBMPO on a Pendulum environment │ │ │ wrapper. │ │ pendulum-ppo │ Run PPO on Pendulum-v1. │ │ pendulum-sac │ Run SAC on Pendulum-v1. │ │ pendulum-td3 │ Run TD3 on Pendulum-v1. │ │ pong-a3c │ Runs A3C on the PongDeterministic-v4 │ │ │ environment. │ │ pong-apex-dqn │ Runs Apex DQN on PongNoFrameskip-v4. │ │ pong-appo │ Runs APPO on PongNoFrameskip-v4. │ │ pong-dqn │ Run DQN on PongDeterministic-v4. │ │ pong-impala │ Run IMPALA on PongNoFrameskip-v4. │ │ pong-ppo │ Run PPO on PongNoFrameskip-v4. │ │ pong-rainbow │ Run Rainbow on PongDeterministic-v4. │ │ recsys-bandits │ Runs BanditLinUCB on a Recommendation │ │ │ Simulation environment. │ │ recsys-long-term-slateq │ Run SlateQ on a recommendation system │ │ │ aimed at long-term satisfaction. │ │ recsys-parametric-slateq │ SlateQ run on a recommendation system. │ │ recsys-ppo │ Run PPO on a recommender system example │ │ │ from RLlib. │ │ recsys-slateq │ SlateQ run on a recommendation system. │ │ repeatafterme-ppo │ Run PPO on RLlib's RepeatAfterMe │ │ │ environment. │ │ stateless-cartpole-r2d2 │ Run R2D2 on a stateless cart pole │ │ │ environment. │ │ swimmer-ars │ Runs ARS on Swimmer-v2. │ │ two-step-game-maddpg │ Run RLlib's Two-step game with multi-agent │ │ │ DDPG. │ │ two-step-game-qmix │ Run QMIX on RLlib's two-step game. │ │ walker2d-ppo │ Run PPO on the Walker2d-v1 environment. │ └─────────────────────────────────┴────────────────────────────────────────────┘ Run any RLlib example as using 'rllib example run <Example ID>'.See 'rllib example run --help' for more information.
An example that is available is called cartpole-ppo, which utilizes the PPO algorithm to solve the cartpole problem in the CartPole-v1 environment from OpenAI Gym (https://gymnasium.farama.org/environments/classic_control/cart_pole/). You can access the configuration of this example by entering rllib example get cartpole-ppo in the command line. This will first download the example file from GitHub and then display the configuration, which is written in YAML format.
! rllib example get cartpole-ppo
>>> Attempting to download example file https://raw.githubusercontent.com/ray-project/ray/master/rllib/tuned_examples/ppo/cartpole-ppo.yaml...
b'cartpole-ppo:\n env: CartPole-v1\n run: PPO\n stop:\n episode_reward_mean: 150\n timesteps_total: 100000\n config:\n # Works for both torch and tf.\n framework: tf\n gamma: 0.99\n lr: 0.0003\n num_workers: 1\n observation_filter: MeanStdFilter\n num_sgd_iter: 6\n vf_loss_coeff: 0.01\n model:\n fcnet_hiddens: [32]\n fcnet_activation: linear\n vf_share_layers: true\n enable_connectors: true\n'
Status code: 200
Downloaded example file to /var/folders/y_/l41py1sx7bl5n30jygrsv0q40000gn/T/tmpnobuu1ka.yaml
cartpole-ppo:
env: CartPole-v1
run: PPO
stop:
episode_reward_mean: 150
timesteps_total: 100000
config:
# Works for both torch and tf.
framework: tf
gamma: 0.99
lr: 0.0003
num_workers: 1
observation_filter: MeanStdFilter
num_sgd_iter: 6
vf_loss_coeff: 0.01
model:
fcnet_hiddens: [32]
fcnet_activation: linear
vf_share_layers: true
enable_connectors: true
While the specific details of the configuration file are not relevant at this time, it is important to note that you must include the Cartpole-v1 environment and the necessary RL configuration for the training process to function properly. You do not need any special equipment to run this configuration, and it should only take a few minutes to complete. In order to train this example, you will need to install the PyGame dependency by using the command pip install pygame, and then simply run:
! rllib example run cartpole-ppo
If you run this, RLlib creates a named experiment and logs important metrics such as
the reward, or the episode_reward_mean for you. In the output of the training run,
you should also see information about the machine (loc, meaning host name and
port), as well as the status of your training runs. If your run is TERMINATED, but you’ve
never seen a successfully RUNNING experiment in the log, something must have gone
wrong. Here’s a sample snippet of a training run:
{text}
+-----------------------------+----------+----------------+
| Trial name | status | loc |
|-----------------------------+----------+----------------|
| PPO_CartPole-v0_9931e_00000 | RUNNING | 127.0.0.1:8683 |
+-----------------------------+----------+----------------+When the training run finishes and things went well, you should see the following output:
{text}
Your training finished.
Best available checkpoint for each trial:
<checkpoint-path>/checkpoint_<number>
You can now evaluate your trained algorithm from any checkpoint,
e.g. by running:
╭─────────────────────────────────────────────────────────────────────────╮
│ rllib evaluate <checkpoint-path>/checkpoint_<number> --algo PPO │
╰─────────────────────────────────────────────────────────────────────────╯Your local Ray checkpoint folder is ~/ray-results by default. For the training
configuration we used, your <checkpoint-path> should be of the form
~/ray_results/cartpole-ppo/PPO_CartPole-v1_<experiment_id>. During training
procedure, your intermediate and final model checkpoints get generated into this
folder.
To evaluate the performance of your trained RL algorithm, you can now evaluate it from checkpoint by copying the command the previous example training run printed:
! rllib evaluate <checkpoint-path>/checkpoint_<number> --algo PPO
Executing this command will display the rewards obtained by the RL algorithm you trained in the CartPole-v1 environment. There is a lot more that can be done with RLlib, which will be discussed further in Chapter 4. The purpose of this example was to demonstrate how easy it is to begin using RLlib and the rllib command line tool through the use of the example and evaluate commands.
Ray Train¶
If you are interested in using Ray for supervised learning, rather than just reinforcement learning, you can use the Ray Train library. However, we do not have enough expertise with frameworks like TensorFlow to provide a detailed example of how to use Ray Train at this time. If you want to learn more about distributed training, you can move on to Chapter 6.
Ray Tune¶
Naming things is hard, but the Ray team hit the spot with Ray Tune, which you can use to tune all sorts of parameters. Specifically, it was built to find good hyperparameters for machine learning models. The typical setup is as follows:
- You want to run an extremely computationally expensive training function. In ML it's not uncommon to run training procedures that take days, if not weeks, but let's say you're dealing with just a couple of minutes.
- As result of training, you compute a so-called objective function. Usually you either want to maximize your gains or minimize your losses in terms of performance of your experiment.
- The tricky bit is that your training function might depend on certain parameters, hyperparameters, that influence the value of your objective function.
- You may have a hunch what individual hyperparameters should be, but tuning them all can be difficult. Even if you can restrict these parameters to a sensible range, it's usually prohibitive to test a wide range of combinations. Your training function is simply too expensive.
What can you do to efficiently sample hyperparameters and get "good enough" results on your objective? The field concerned with solving this problem is called hyperparameter optimization (HPO), and Ray Tune has an enormous suite of algorithms for tackling it. Let's look at a first example of Ray Tune used for the situation we just explained. The focus is yet again on Ray and its API, and not on a specific ML task (which we simply simulate for now).
from ray import tune
import math
import time
def training_function(config):
x, y = config["x"], config["y"]
time.sleep(10)
score = objective(x, y)
tune.report(score=score)
def objective(x, y):
return math.sqrt((x**2 + y**2)/2)
result = tune.run(
training_function,
config={
"x": tune.grid_search([-1, -.5, 0, .5, 1]),
"y": tune.grid_search([-1, -.5, 0, .5, 1])
})
print(result.get_best_config(metric="score", mode="min"))
Tune Status
| Current time: | 2022-12-20 10:12:03 |
| Running for: | 00:00:32.62 |
| Memory: | 18.1/32.0 GiB |
System Info
Using FIFO scheduling algorithm.Resources requested: 0/12 CPUs, 0/0 GPUs, 0.0/12.03 GiB heap, 0.0/2.0 GiB objects
Trial Status
| Trial name | status | loc | x | y | iter | total time (s) | score |
|---|---|---|---|---|---|---|---|
| training_function_4a371_00000 | TERMINATED | 127.0.0.1:42585 | -1 | -1 | 1 | 10.0019 | 1 |
| training_function_4a371_00001 | TERMINATED | 127.0.0.1:42588 | -0.5 | -1 | 1 | 10.0041 | 0.790569 |
| training_function_4a371_00002 | TERMINATED | 127.0.0.1:42589 | 0 | -1 | 1 | 10.0009 | 0.707107 |
| training_function_4a371_00003 | TERMINATED | 127.0.0.1:42594 | 0.5 | -1 | 1 | 10.0019 | 0.790569 |
| training_function_4a371_00004 | TERMINATED | 127.0.0.1:42595 | 1 | -1 | 1 | 10.0038 | 1 |
| training_function_4a371_00005 | TERMINATED | 127.0.0.1:42596 | -1 | -0.5 | 1 | 10.0049 | 0.790569 |
| training_function_4a371_00006 | TERMINATED | 127.0.0.1:42597 | -0.5 | -0.5 | 1 | 10.0006 | 0.5 |
| training_function_4a371_00007 | TERMINATED | 127.0.0.1:42598 | 0 | -0.5 | 1 | 10.0045 | 0.353553 |
| training_function_4a371_00008 | TERMINATED | 127.0.0.1:42599 | 0.5 | -0.5 | 1 | 10.0016 | 0.5 |
| training_function_4a371_00009 | TERMINATED | 127.0.0.1:42600 | 1 | -0.5 | 1 | 10.0055 | 0.790569 |
| training_function_4a371_00010 | TERMINATED | 127.0.0.1:42601 | -1 | 0 | 1 | 10.0053 | 0.707107 |
| training_function_4a371_00011 | TERMINATED | 127.0.0.1:42602 | -0.5 | 0 | 1 | 10.001 | 0.353553 |
| training_function_4a371_00012 | TERMINATED | 127.0.0.1:42585 | 0 | 0 | 1 | 10.0029 | 0 |
| training_function_4a371_00013 | TERMINATED | 127.0.0.1:42595 | 0.5 | 0 | 1 | 10.0044 | 0.353553 |
| training_function_4a371_00014 | TERMINATED | 127.0.0.1:42596 | 1 | 0 | 1 | 10.0054 | 0.707107 |
| training_function_4a371_00015 | TERMINATED | 127.0.0.1:42588 | -1 | 0.5 | 1 | 10.0045 | 0.790569 |
| training_function_4a371_00016 | TERMINATED | 127.0.0.1:42598 | -0.5 | 0.5 | 1 | 10.0047 | 0.5 |
| training_function_4a371_00017 | TERMINATED | 127.0.0.1:42597 | 0 | 0.5 | 1 | 10.0044 | 0.353553 |
| training_function_4a371_00018 | TERMINATED | 127.0.0.1:42601 | 0.5 | 0.5 | 1 | 10.0051 | 0.5 |
| training_function_4a371_00019 | TERMINATED | 127.0.0.1:42600 | 1 | 0.5 | 1 | 10.0033 | 0.790569 |
| training_function_4a371_00020 | TERMINATED | 127.0.0.1:42602 | -1 | 1 | 1 | 10.0022 | 1 |
| training_function_4a371_00021 | TERMINATED | 127.0.0.1:42599 | -0.5 | 1 | 1 | 10.0043 | 0.790569 |
| training_function_4a371_00022 | TERMINATED | 127.0.0.1:42589 | 0 | 1 | 1 | 10.0034 | 0.707107 |
| training_function_4a371_00023 | TERMINATED | 127.0.0.1:42594 | 0.5 | 1 | 1 | 10.005 | 0.790569 |
| training_function_4a371_00024 | TERMINATED | 127.0.0.1:42585 | 1 | 1 | 1 | 10.0043 | 1 |
Trial Progress
| Trial name | date | done | episodes_total | experiment_id | experiment_tag | hostname | iterations_since_restore | node_ip | pid | score | time_since_restore | time_this_iter_s | time_total_s | timestamp | timesteps_since_restore | timesteps_total | training_iteration | trial_id | warmup_time |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| training_function_4a371_00000 | 2022-12-20_10-11-43 | True | 494ed1a59d494bc6ba4760cbe8657871 | 0_x=-1,y=-1 | mac | 1 | 127.0.0.1 | 42585 | 1 | 10.0019 | 10.0019 | 10.0019 | 1671527503 | 0 | 1 | 4a371_00000 | 0.00247288 | ||
| training_function_4a371_00001 | 2022-12-20_10-11-47 | True | b9bf7326ef8b476dbedd8df0c7f34f73 | 1_x=-0.5000,y=-1 | mac | 1 | 127.0.0.1 | 42588 | 0.790569 | 10.0041 | 10.0041 | 10.0041 | 1671527507 | 0 | 1 | 4a371_00001 | 0.0415869 | ||
| training_function_4a371_00002 | 2022-12-20_10-11-47 | True | a4efaf055d5c4bdf8b03404e0fd2bc34 | 2_x=0,y=-1 | mac | 1 | 127.0.0.1 | 42589 | 0.707107 | 10.0009 | 10.0009 | 10.0009 | 1671527507 | 0 | 1 | 4a371_00002 | 0.030731 | ||
| training_function_4a371_00003 | 2022-12-20_10-11-47 | True | 2a144f96ed2a4e8ab45e404c3b978e7b | 3_x=0.5000,y=-1 | mac | 1 | 127.0.0.1 | 42594 | 0.790569 | 10.0019 | 10.0019 | 10.0019 | 1671527507 | 0 | 1 | 4a371_00003 | 0.0482671 | ||
| training_function_4a371_00004 | 2022-12-20_10-11-47 | True | 86caff41ea4349d9899ab098d96626c9 | 4_x=1,y=-1 | mac | 1 | 127.0.0.1 | 42595 | 1 | 10.0038 | 10.0038 | 10.0038 | 1671527507 | 0 | 1 | 4a371_00004 | 0.010777 | ||
| training_function_4a371_00005 | 2022-12-20_10-11-47 | True | ef976c7e3f9845299c91f579117b872f | 5_x=-1,y=-0.5000 | mac | 1 | 127.0.0.1 | 42596 | 0.790569 | 10.0049 | 10.0049 | 10.0049 | 1671527507 | 0 | 1 | 4a371_00005 | 0.0338681 | ||
| training_function_4a371_00006 | 2022-12-20_10-11-47 | True | 2f2885ae2c744505a1ec68f43fbe9ede | 6_x=-0.5000,y=-0.5000 | mac | 1 | 127.0.0.1 | 42597 | 0.5 | 10.0006 | 10.0006 | 10.0006 | 1671527507 | 0 | 1 | 4a371_00006 | 0.0315561 | ||
| training_function_4a371_00007 | 2022-12-20_10-11-47 | True | a5091dce37d342a2b6af5fa1fbecdbf4 | 7_x=0,y=-0.5000 | mac | 1 | 127.0.0.1 | 42598 | 0.353553 | 10.0045 | 10.0045 | 10.0045 | 1671527507 | 0 | 1 | 4a371_00007 | 0.030849 | ||
| training_function_4a371_00008 | 2022-12-20_10-11-47 | True | d8f205e32fbc4666a32aa1ec410c29d0 | 8_x=0.5000,y=-0.5000 | mac | 1 | 127.0.0.1 | 42599 | 0.5 | 10.0016 | 10.0016 | 10.0016 | 1671527507 | 0 | 1 | 4a371_00008 | 0.038857 | ||
| training_function_4a371_00009 | 2022-12-20_10-11-47 | True | 9efc9400e11341b08a1eb705830ae780 | 9_x=1,y=-0.5000 | mac | 1 | 127.0.0.1 | 42600 | 0.790569 | 10.0055 | 10.0055 | 10.0055 | 1671527507 | 0 | 1 | 4a371_00009 | 0.00727797 | ||
| training_function_4a371_00010 | 2022-12-20_10-11-47 | True | eebcc54cdc334cbf981f4688b3808a3b | 10_x=-1,y=0 | mac | 1 | 127.0.0.1 | 42601 | 0.707107 | 10.0053 | 10.0053 | 10.0053 | 1671527507 | 0 | 1 | 4a371_00010 | 0.02653 | ||
| training_function_4a371_00011 | 2022-12-20_10-11-47 | True | 5bf52487723542b596e3e48a3bb3e08d | 11_x=-0.5000,y=0 | mac | 1 | 127.0.0.1 | 42602 | 0.353553 | 10.001 | 10.001 | 10.001 | 1671527507 | 0 | 1 | 4a371_00011 | 0.0319781 | ||
| training_function_4a371_00012 | 2022-12-20_10-11-53 | True | 494ed1a59d494bc6ba4760cbe8657871 | 12_x=0,y=0 | mac | 1 | 127.0.0.1 | 42585 | 0 | 10.0029 | 10.0029 | 10.0029 | 1671527513 | 0 | 1 | 4a371_00012 | 0.00247288 | ||
| training_function_4a371_00013 | 2022-12-20_10-11-57 | True | 86caff41ea4349d9899ab098d96626c9 | 13_x=0.5000,y=0 | mac | 1 | 127.0.0.1 | 42595 | 0.353553 | 10.0044 | 10.0044 | 10.0044 | 1671527517 | 0 | 1 | 4a371_00013 | 0.010777 | ||
| training_function_4a371_00014 | 2022-12-20_10-11-57 | True | ef976c7e3f9845299c91f579117b872f | 14_x=1,y=0 | mac | 1 | 127.0.0.1 | 42596 | 0.707107 | 10.0054 | 10.0054 | 10.0054 | 1671527517 | 0 | 1 | 4a371_00014 | 0.0338681 | ||
| training_function_4a371_00015 | 2022-12-20_10-11-57 | True | b9bf7326ef8b476dbedd8df0c7f34f73 | 15_x=-1,y=0.5000 | mac | 1 | 127.0.0.1 | 42588 | 0.790569 | 10.0045 | 10.0045 | 10.0045 | 1671527517 | 0 | 1 | 4a371_00015 | 0.0415869 | ||
| training_function_4a371_00016 | 2022-12-20_10-11-57 | True | a5091dce37d342a2b6af5fa1fbecdbf4 | 16_x=-0.5000,y=0.5000 | mac | 1 | 127.0.0.1 | 42598 | 0.5 | 10.0047 | 10.0047 | 10.0047 | 1671527517 | 0 | 1 | 4a371_00016 | 0.030849 | ||
| training_function_4a371_00017 | 2022-12-20_10-11-57 | True | 2f2885ae2c744505a1ec68f43fbe9ede | 17_x=0,y=0.5000 | mac | 1 | 127.0.0.1 | 42597 | 0.353553 | 10.0044 | 10.0044 | 10.0044 | 1671527517 | 0 | 1 | 4a371_00017 | 0.0315561 | ||
| training_function_4a371_00018 | 2022-12-20_10-11-57 | True | eebcc54cdc334cbf981f4688b3808a3b | 18_x=0.5000,y=0.5000 | mac | 1 | 127.0.0.1 | 42601 | 0.5 | 10.0051 | 10.0051 | 10.0051 | 1671527517 | 0 | 1 | 4a371_00018 | 0.02653 | ||
| training_function_4a371_00019 | 2022-12-20_10-11-57 | True | 9efc9400e11341b08a1eb705830ae780 | 19_x=1,y=0.5000 | mac | 1 | 127.0.0.1 | 42600 | 0.790569 | 10.0033 | 10.0033 | 10.0033 | 1671527517 | 0 | 1 | 4a371_00019 | 0.00727797 | ||
| training_function_4a371_00020 | 2022-12-20_10-11-57 | True | 5bf52487723542b596e3e48a3bb3e08d | 20_x=-1,y=1 | mac | 1 | 127.0.0.1 | 42602 | 1 | 10.0022 | 10.0022 | 10.0022 | 1671527517 | 0 | 1 | 4a371_00020 | 0.0319781 | ||
| training_function_4a371_00021 | 2022-12-20_10-11-57 | True | d8f205e32fbc4666a32aa1ec410c29d0 | 21_x=-0.5000,y=1 | mac | 1 | 127.0.0.1 | 42599 | 0.790569 | 10.0043 | 10.0043 | 10.0043 | 1671527517 | 0 | 1 | 4a371_00021 | 0.038857 | ||
| training_function_4a371_00022 | 2022-12-20_10-11-57 | True | a4efaf055d5c4bdf8b03404e0fd2bc34 | 22_x=0,y=1 | mac | 1 | 127.0.0.1 | 42589 | 0.707107 | 10.0034 | 10.0034 | 10.0034 | 1671527517 | 0 | 1 | 4a371_00022 | 0.030731 | ||
| training_function_4a371_00023 | 2022-12-20_10-11-57 | True | 2a144f96ed2a4e8ab45e404c3b978e7b | 23_x=0.5000,y=1 | mac | 1 | 127.0.0.1 | 42594 | 0.790569 | 10.005 | 10.005 | 10.005 | 1671527517 | 0 | 1 | 4a371_00023 | 0.0482671 | ||
| training_function_4a371_00024 | 2022-12-20_10-12-03 | True | 494ed1a59d494bc6ba4760cbe8657871 | 24_x=1,y=1 | mac | 1 | 127.0.0.1 | 42585 | 1 | 10.0043 | 10.0043 | 10.0043 | 1671527523 | 0 | 1 | 4a371_00024 | 0.00247288 |
2022-12-20 10:12:03,528 INFO tune.py:762 -- Total run time: 33.58 seconds (32.61 seconds for the tuning loop).
{'x': 0, 'y': 0}
Note how the output of this run is structurally similar to what you’ve
seen in the RLlib example. That’s no coincidence, as RLlib (like many other Ray
libraries) uses Ray Tune under the hood. If you look closely, you will see PENDING
runs that wait for execution, as well as RUNNING and TERMINATED runs. Tune takes care
of selecting, scheduling, and executing your training runs for you automatically.
This Tune example aims to identify the optimal values for parameters x and y for a training_function with the goal of minimizing a particular objective. Although the objective function may seem complicated as it involves calculating the sum of the squares of x and y, all of the values will be non-negative. Therefore, the lowest value is achieved when x and y are both equal to 0, resulting in an evaluation of 0 for the objective function.
We do a so-called grid search over all possible parameter combinations. As we explicitly pass in five possible values for both x and y that’s a total of 25 combinations that get fed into the training function. These combinations are evaluated through the training function, which includes a 10 second sleep time. Without Ray's ability to parallelize the process, testing all of these combinations would take more than four minutes. However, on my laptop, this experiment only takes around 35 seconds to complete. The duration may vary depending on the device used.
If each training run took several hours, and there were 20 hyperparameters to consider instead of just two, it would not be practical to use grid search. This is especially true if you do not have a good idea of what range the parameters should be in. In these cases, you will need to use more advanced HPO methods like those offered by Ray Tune, which we will discuss in Chapter 5.
Ray Serve¶
The last of Ray's high-level libraries we'll discuss specializes on model serving and is simply called Ray Serve. To see an example of it in action, you need a trained ML model to serve. Luckily, nowadays you can find many interesting models on the internet that have already been trained for you. For instance, Hugging Face has a variety of models available for you to download directly in Python. The model we'll use is a language model called GPT-2 that takes text as input and produces text to continue or complete the input. For example, you can prompt a question and GPT-2 will try to complete it.
Serving such a model is a good way to make it accessible. You may not now how to load and run a TensorFlow model on your computer, but you do now how to ask a question in plain English. Model serving hides the implementation details of a solution and lets users focus on providing inputs and understanding outputs of a model.
To proceed, make sure to run pip install transformers to install the Hugging Face library
that has the model we want to use.
With that we can now import and start an instance of Ray's serve library, load and deploy a GPT-2
model and ask it for the meaning of life, like so:
from ray import serve
from transformers import pipeline
import requests
serve.start()
@serve.deployment
def model(request):
language_model = pipeline("text-generation", model="gpt2")
query = request.query_params["query"]
return language_model(query, max_length=100)
model.deploy()
query = "What's the meaning of life?"
response = requests.get(f"http://localhost:8000/model?query={query}")
print(response.text)
In Chapter 9, you will be taught how to correctly implement models in various situations. However, for now, I recommend that you experiment with this example and try different queries. If you repeatedly run the last two lines of code, you will get practically different answers every time. Here is a poetic statement that I queried on my computer, which has been slightly edited for younger readers:
{text}
[{
"generated_text": "What's the meaning of life?\n\n
Is there one way or another of living?\n\n
How does it feel to be trapped in a relationship?\n\n
How can it be changed before it's too late?
What did we call it in our time?\n\n
Where do we fit within this world and what are we going to live for?\n\n
My life as a person has been shaped by the love I've received from others."
}]This is the end of our overview of the data science libraries within the second layer of Ray. These libraries, which we have discussed in this chapter, are all based on the Ray Core API. It is fairly simple to create new extensions for Ray, and there are a few more that we are unable to cover in this book. For example, the Ray Workflows library (https://docs.ray.io/en/latest/workflows/concepts.html) allows users to define and run long-term applications using Ray. Before we conclude this chapter, let's briefly examine the third layer of Ray, which is the expanding ecosystem surrounding the platform.
The Ray Ecosystem¶
Ray's libraries are powerful and should be discussed in more detail in the book. Although they are very useful for data science work, we don't want to give the impression that they are the only thing you need from now on. The most successful frameworks are those that work well with other solutions and ideas. It is better to concentrate on your strengths and use other tools to fill any gaps in your solution, which Ray does well.
Throughout the book, we will be discussing various libraries that have been built on top of Ray. Additionally, Ray has integrations with existing tools like Spark, Dask, and Pandas. For instance, you can use Ray Datasets, a data loading and compute library, with your existing project that utilizes data processing engines like Spark or Dask. Additionally, you can run the entire Dask ecosystem on a Ray cluster with the Dask-on-Ray scheduler or use the Spark on Ray project to integrate your Spark workloads with Ray. The Modin project also offers a distributed replacement for Pandas dataframes that utilizes Ray or Dask as the distributed execution engine.
Ray's approach is to integrate with various tools rather than trying to replace them, while still providing access to its own native library called Ray Datasets. This will be explored in more detail later in Chapter 11. It's noteworthy that many of the Ray libraries have the ability to seamlessly integrate with other tools as backends, often by creating common interfaces rather than establishing new standards. These interfaces enable you to perform tasks in a distributed manner, something that many of the backends may not offer or may not offer to the same degree.
For example, Ray RLlib and Train both utilize the capabilities of TensorFlow and PyTorch. Additionally, Ray Tune allows for the use of a variety of HPO tools, such as Hyperopt, Optuna, Nevergrad, Ax, and SigOpt, among others. These tools are not automatically distributed, but Tune brings them together in a unified interface for distributed tasks.